概述
今天主要总结一下MySQL数据库的聚集索引和非聚集索引,下面一起来看看吧!
一、 MYSQL的索引
mysql中,不同的存储引擎对索引的实现方式不同,先说下MyISAM和InnoDB两种存储引擎。
MyISAM的B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的。这里的索引都是非聚簇索引。MyISAM还采用压缩机制存储索引,比如,第一个索引为“her”,第二个索引为“here”,那么第二个索引会被存储为“3,e”,这样的缺点是同一个节点中的索引只能采用顺序查找。
InnoDB的数据文件本身就是索引文件,B+Tree的叶子节点上的data就是数据本身,key为主键,这是聚簇索引。非聚簇索引,叶子节点上的data是主键(所以聚簇索引的key,不能过长)。为什么存放的主键,而不是记录所在地址呢,理由相当简单,因为记录所在地址并不能保证一定不会变,但主键可以保证。
至于为什么主键通常建议使用自增id呢?
二、聚簇索引
1、概念
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。
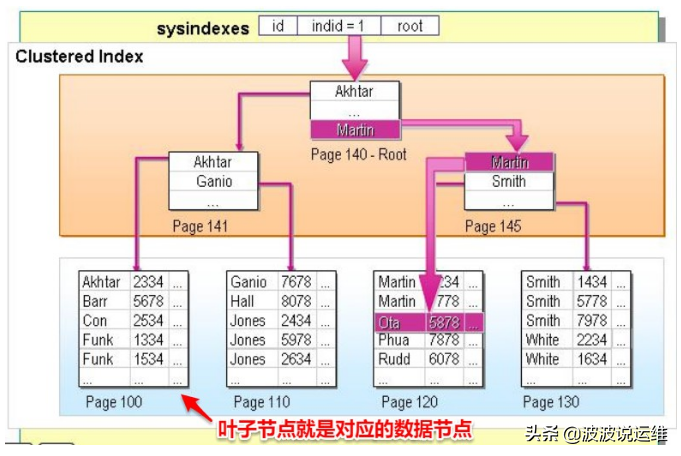
聚簇索引不但在检索上可以大大滴提高效率,在数据读取上也一样。比如:需要查询f~t的所有单词。
一个使用MyISAM的主索引,一个使用InnoDB的聚簇索引。两种索引的B+Tree检索时间一样,但读取时却有了差异。
因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停的寻道不停的旋转。聚簇索引则只需一次I/O。
不过,如果涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
鉴于聚簇索引的范围查询效率,很多人认为使用主键作为聚簇索引太多浪费,毕竟几乎不会使用主键进行范围查询。但若再考虑到聚簇索引的存储,就不好定论了。
2、建立聚簇索引的思想:
- 1、大多数表都应该有聚簇索引或使用分区来降低对表尾页的竞争,在一个高事务的环境中,对最后一页的封锁严重影响系统的吞吐量。
- 2、在聚簇索引下,数据在物理上按顺序排在数据页上,重复值也排在一起,因而在那些包含范围检查(between、<、<=、>、>=)或使用group by或orderby的查询时,一旦找到具有范围中第一个键值的行,具有后续索引值的行保证物理上毗连在一起而不必进一步搜索,避免了大范围扫描,可以大大提高查询速度。
- 3、在一个频繁发生插入操作的表上建立聚簇索引时,不要建在具有单调上升值的列(如IDENTITY)上,否则会经常引起封锁冲突。
- 4、在聚簇索引中不要包含经常修改的列,因为码值修改后,数据行必须移动到新的位置。
- 5、选择聚簇索引应基于where子句和连接操作的类型。
3、聚簇索引的侯选列:
- 1、主键列,该列在where子句中使用并且插入是随机的。
- 2、按范围存取的列,如pri_order > 100 and pri_order < 200。
- 3、在group by或order by中使用的列。
- 4、不经常修改的列。
- 5、在连接操作中使用的列。
三、 非聚簇索引(新华字典的偏旁字典,结构顺序与实际存放顺序不一定一致)
1、概念
非聚簇索引,叶级页指向表中的记录,记录的物理顺序与逻辑顺序没有必然的联系。非聚簇索引则更像书的标准索引表,索引表中的顺序通常与实际的页码顺序是不一致的。非聚集索引叶节点仍然是索引节点,只是有一个指针指向对应的数据块,如果使用非聚集索引查询,而查询列中包含了其他该索引没有覆盖的列,那么他还要进行第二次的查询,查询节点上对应的数据行的数据。

每个表只能有一个聚簇索引,因为一个表中的记录只能以一种物理顺序存放。但是,一个表可以有不止一个非聚簇索引。实际上,对每个表你最多可以建立249个非聚簇索引。非聚簇索引需要大量的硬盘空间和内存。另外,虽然非聚簇索引可以提高从表中取数据的速度,它也会降低向表中插入和更新数据的速度。每当你改变了一个建立了非聚簇索引的表中的数据时,必须同时更新索引。因此你对一个表建立非聚簇索引时要慎重考虑。如果你预计一个表需要频繁地更新数据,那么不要对它建立太多非聚簇索引。另外,如果硬盘和内存空间有限,也应该限制使用非聚簇索引的数量。
2、非聚簇索引的使用:
非聚簇索引不重新组织表中的数据,而是对每一行存储索引列值并用一个指针指向数据所在的页面。每个非聚簇索引提供访问数据的不同排序顺序。在建立非聚簇索引时,要权衡索引对查询速度的加快与降低修改速度之间的利弊。另外,还要考虑这些问题:
- 1、索引需要使用多少空间。
- 2、合适的列是否稳定。
- 3、索引键是如何选择的,扫描效果是否更佳。
- 4、是否有许多重复值。
对更新频繁的表来说,表上的非聚簇索引比聚簇索引和根本没有索引需要更多的额外开销。对移到新页的每一行而言,指向该数据的每个非聚簇索引的页级行也必须更新,有时可能还需要索引页的分理。从一个页面删除数据的进程也会有类似的开销,另外,删除进程还必须把数据移到页面上部,以保证数据的连续性。所以,建立非聚簇索引要非常慎重。非聚簇索引常被用在以下情况:
- 1、某列常用于集合函数(如Sum,....)。
- 2、某列常用于join,order by,group by。
- 3、查寻出的数据不超过表中数据量的20%。
四、使用场景
