概述
下面主要分享一个最近测试的mysql实验,帮助大家理解一下mysql数据库的联接查询算法。
mysql联接过程测试
创建测试表如下:
CREATE TABLE t1 (m1 int, n1 char(1)); CREATE TABLE t2 (m2 int, n2 char(1)); INSERT INTO t1 VALUES(1, 'a'), (2, 'b'), (3, 'c'); INSERT INTO t2 VALUES(2, 'b'), (3, 'c'), (4, 'd'), (5, 'e'), (6, 'f'); commit;
联接操作的本质就是把各个联接表中的记录都取出来依次匹配的组合加入结果集并返回给用户。如果没有任何限制条件的话,多表联接起来产生的笛卡尔积可能是非常巨大的。比方说3个100行记录的表联接起来产生的笛卡尔积就有100×100×100=1000000行数据!所以在联接的时候过滤掉特定记录组合是有必要的,在联接查询中的过滤条件可以分成两种,我们以一个JOIN查询为例:
SELECT * FROM t1, t2 WHERE t1.m1 > 1 AND t1.m1 = t2.m2 AND t2.n2 <'d';
- 涉及单表的条件
WHERE条件也可以称为搜索条件,比如t1.m1 > 1是只针对t1表的过滤条件,t2.n2 < 'd'是只针对t2表的过滤条件。
- 涉及两表的条件
比如t1.m1 = t2.m2、t1.n1 > t2.n2等,这些条件中涉及到了两个表。
在这个查询中指明了这三个过滤条件:
1. t1.m1 > 1 2. t1.m1 = t2.m2 3. t2.n2 < ‘d’
那么这个联接查询的大致执行过程如下:
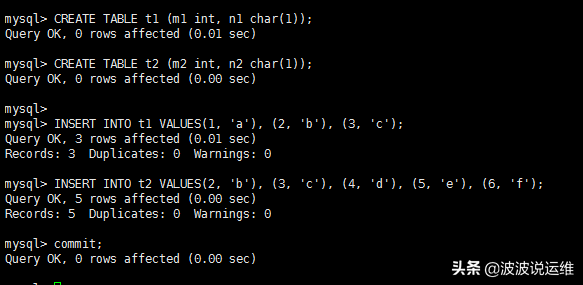
首先确定第一个需要查询的表,这个表称之为驱动表。怎样在单表中执行查询语句,只需要选取代价最小的那种访问方法去执行单表查询语句就好了(就是说从const、ref、ref_or_null、range、index、all这些执行方法中选取代价最小的去执行查询)。此处假设使用t1作为驱动表,那么就需要到t1表中找满足t1.m1 > 1的记录,假设这里并没有给t1字段添加索引,所以此处查询t1表的访问方法就设定为all吧,也就是采用全表扫描的方式执行单表查询。所以查询过程就如下图所示:
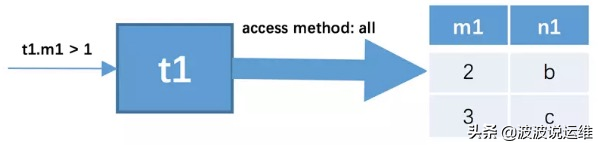
针对上一步骤中从驱动表产生的结果集中的每一条记录,分别需要到t2表中查找匹配的记录,所谓匹配的记录,指的是符合过滤条件的记录。因为是根据t1表中的记录去找t2表中的记录,所以t2表也可以被称之为被驱动表。比如上一步骤从驱动表中得到了2条记录,所以需要查询2次t2表。此时涉及两个表的列的过滤条件t1.m1 = t2.m2就派上用场了:
- 当t1.m1 = 2时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 2,所以此时t2表相当于有了t1.m1 = 2、t2.n2 < ‘d’这两个过滤条件,然后到t2表中执行单表查询。
- 当t1.m1 = 3时,过滤条件t1.m1 = t2.m2就相当于t2.m2 = 3,所以此时t2表相当于有了t1.m1 = 3、t2.n2 < ‘d’这两个过滤条件,然后到t2表中执行单表查询。
所以整个联接查询的执行过程就如下图所示:
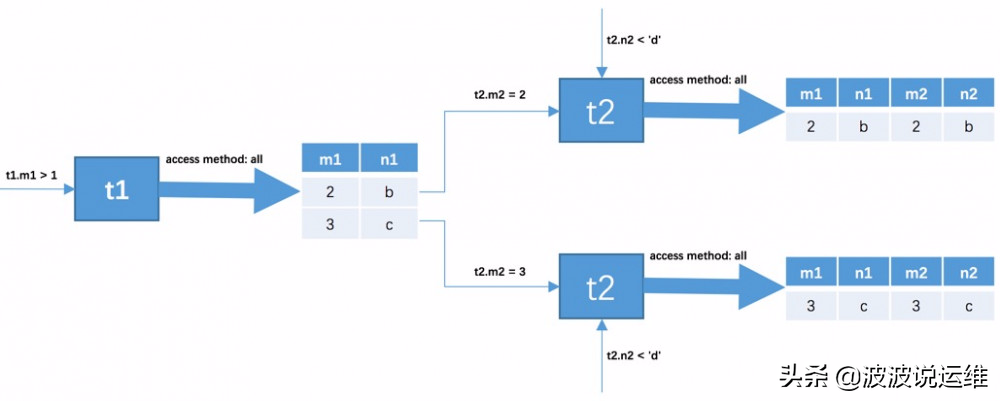
也就是说整个联接查询最后的结果只有两条符合过滤条件的记录:
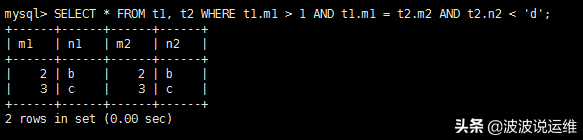
从上边两个步骤可以看出来,我们上边说的这个两表联接查询共需要查询1次t1表,2次t2表。当然这是在特定的过滤条件下的结果,如果我们把t1.m1 > 1这个条件去掉,那么从t1表中查出的记录就有3条,就需要查询3次t3表了。也就是说在两表联接查询中,驱动表只需要访问一次,被驱动表可能被访问多次,这种方式在MySQL中有一个专有名词,叫Nested-Loops Join(嵌套循环联接)。我们在真正使用MySQL的时候表动不动就是几百上千万数据,如果都按照Nested-Loops Join算法,一次Join查询的代价也太大了。
mysql联接算法介绍
联接算法是MySQL数据库用于处理联接的物理策略。目前MySQL数据库仅支持Nested-Loops Join算法。而MySQL的分支版本MariaDB除了支持Nested-Loops Join算法外,还支持Classic Hash Join算法。当联接的表上有索引时,Nested-Loops Join是非常高效的算法。根据B+树的特性,其联接的时间复杂度为O(N),若没有索引,则可视为最坏的情况,时间复杂度为O(N²)。
MySQL数据库根据不同的使用场合,支持两种Nested-Loops Join算法,一种是Simple Nested-Loops Join(NLJ)算法,另一种是Block Nested-Loops Join(BNL)算法。
1、Simple Nested-Loops Join(SNLJ,简单嵌套循环联接)
Simple Nested-Loops Join算法相当简单、直接。即外表(驱动表)中的每一条记录与内表(被驱动表)中的记录进行比较判断。对于两表联接来说,驱动表只会被访问一遍,但被驱动表却要被访问到好多遍,具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。
对于内联接来说,选取哪个表为驱动表都没关系,而外联接的驱动表是固定的,也就是说左(外)联接的驱动表就是左边的那个表,右(外)联接的驱动表就是右边的那个表(这个只是一般情况,也有左联接驱动表选择右边的表)。
用伪代码表示一下这个过程就是这样:
For each row r in R do -- 扫描R表(驱动表) For each row s in S do -- 扫描S表(被驱动表) If r and s satisfy the join condition -- 如果r和s满足join条件 Then output the tuple <r, s> -- 返回结果集
下图能更好地显示整个SNLJ的过程:
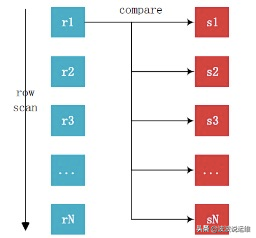
其中R表为外部表(Outer Table),S表为内部表(Inner Table)。这是一个最简单的算法,这个算法的开销其实非常大。
2、Index Nested-Loops Join(INLJ,基于索引的嵌套循环联接)
SNLJ算法虽然简单明了,但是也是相当的粗暴,需要多次访问内表(每一次都是全表扫描)。因此,在Join的优化时候,通常都会建议在内表建立索引,以此降低Nested-Loop Join算法的开销,减少内表扫描次数,MySQL数据库中使用较多的就是这种算法,以下称为INLJ。来看这种算法的伪代码:
For each row r in R do -- 扫描R表 lookup s in S index -- 查询S表的索引(固定3~4次IO,B+树高度) If find s == r -- 如果r匹配了索引s Then output the tuple <r, s> -- 返回结果集
由于内表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。整个过程如下图所示:
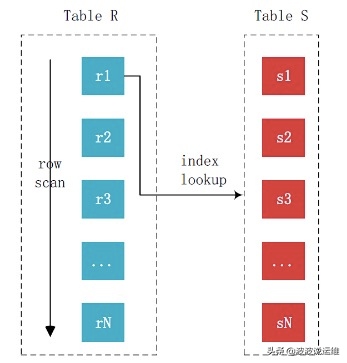
可以看到外表中的每条记录通过内表的索引进行访问,就是读取外部表一行数据,然后去内部表索引进行二分查找匹配;而一般B+树的高度为3~4层,也就是说匹配一次的io消耗也就3~4次。
继续上面的实验,这里给上面的 t1.m1 和 t2.m2 分别添加主键,看一下下面这个内联接的执行计划:
mysql> alter table t1 add primary key(`m1`); mysql> alter table t2 add primary key(`m2`); mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.m1 = t2.m2;
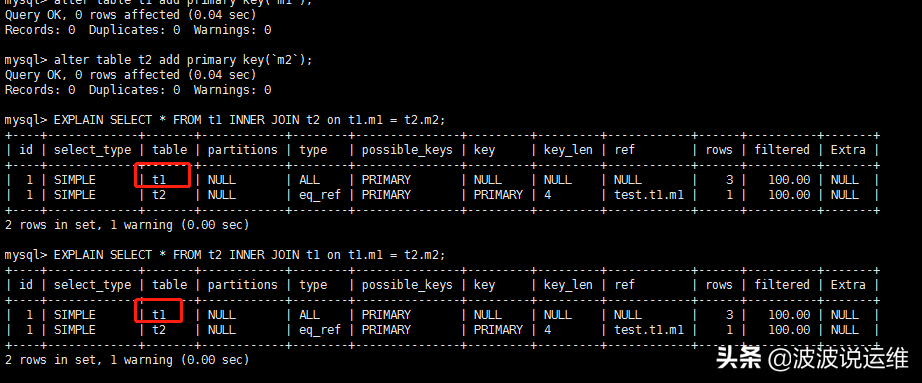
可以看到执行计划是将 t1 表作为驱动表,将 t2 表作为被驱动表,因为对 t2.m2 列的条件是等值查找,比如 t2.m2=2、t2.m2=3 等,所以MySQL把在联接查询中对被驱动表使用主键值或者唯一二级索引列的值进行等值查找的查询执行方式称之为eq_ref。
这里为什么将 t1 作为驱动表?因为表 t1 中的记录少于表 t2,这样联接需要匹配的次数就少了,所以 SQL 优化器选择表 t1 作为驱动表。
若我们执行的 SQL 带有 WHERE 条件时呢?看看不一样的执行计划。如果条件为表 t1 的主键,执行计划如下:
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.m1 = t2.m2 WHERE t1.m1 = 2;

可以看到执行计划算是极优,同时 t1 表还是驱动表,因为经过 WHERE 条件过滤后的数据只有一条(我们知道在单表中使用主键值或者唯一二级索引列的值进行等值查找的方式称之为 const,所以我们可以看到 t1 的 type 为 const;如果这里条件为 t1.m1 > 1,那么自然 type 就为range),同时 t2.m2 也是主键,自然只有一条数据,type 也为 const。
如果 WHERE 条件是一个没有索引的字段呢?执行计划如下:
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.m1 = t2.m2 WHERE t1.n1='a';

从执行计划上看跟不加 WHERE 条件几乎差不多,但是可以看到 filtered 为33%了,而不是 100%,说明需要返回的数据量变少了。另外 Extra 字段中标识使用了 WHERE 条件过滤。
如果 WHERE 条件是一个有索引的字段呢(比如给 t2.n2 添加一个非唯一二级索引)?这里就不得不提 MySQL 一个非常重要的特性了,pushed-down conditions(条件下推)优化。就是把索引条件下推到存储引擎层进行数据的过滤并返回过滤后的数据。那么此时的执行计划就如下:
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.m1 = t2.m2 WHERE t2.n2='a';

可以看到 t2 表成为了驱动表(经过二级索引过滤后数据只有1条,所以这里使用到ref的访问方法)。
如果把 t2.n2 换为范围查询呢?看执行计划如下:
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.m1 = t2.m2 WHERE t2.n2>'a';

可以看到虽然WHERE条件有索引,但由于 t2.n2>’a’ 过滤后的数据还是比 t1 表多,所以优化器就选择了 t1 表作为驱动表。而此时 t2 表的查询条件类似如下:
SELECT * FROM t2 WHERE t2.m2 = 1 AND t2.n2 > 'a';
由于 t2.m2 是主键,t2.n2 有二级索引,优化器平衡了一下,可能觉得 t2.n2 过滤后的数据占全表比例太大,回表的成本比直接访问主键成本要高,所以就直接使用了主键。如果说 t2.n2 过滤后的数据占全表数据比例较小,是有可能会选择 idx_n2 索引。
最后,我们使用 t1.n1 与 t2.n2 作为条件,看一下执行计划如下:
mysql> EXPLAIN SELECT * FROM t1 INNER JOIN t2 on t1.n1 = t2.n2;

这里由于 t2.n2 不是主键或唯一索引,type 类型变成了 ref。
从上面的实验我们可以得出这个结论:联接查询成本占大头的就是“驱动表记录数 乘以 单次访问被驱动表的成本”,所以优化重点其实就是下面这两个部分:
- 尽量减少驱动表的记录数
- 对被驱动表的访问成本尽可能降低
这两点对于我们实际书写联接查询语句时十分有用,我们需要尽量在被驱动表的联接列上建立索引(主键或唯一索引最优,其次是非唯一二级索引),这样就可以使用 eq_ref 或 ref 访问方法来降低访问被驱动表的成本了。