相信大家对小编总结的不做实验发文章的三大套路都耳熟能详了(META、生信和临床研究)。在此再介绍一种SEER数据库分析的文章套路,也可以不做实验轻松发论(guan)文(shui),但是仅限肿瘤研究领域。
SEER数据库收录了美国大量癌症病人的临床信息,覆盖美国约28%的癌症患者。收集了多种类型的癌症,随访时间长,是很好的数据来源。
1、 数据下载
打开主页后,需要下载一个SEER*Stat 软件 ,最新的版本是8.3.4 。还需要申请一个账号,才可以有使用权限,申请以后账号和密码会以邮件形式发送到邮箱。然后打开SEER*Stat 软件,你会看到如下界面,点击红框指示的表格按钮,也就是case listing session,此时需要输入账号密码。
然后就会出现如下对话框。第一栏data就是选择你要的数据来源的范围,SEER数据库貌似最近更新到2014年的随访数据,所以尽量选最新的数据集。

第二栏selection就是选择病例筛选的条件。点击edit,然后会有很多选项,选择你需要的病例范围、肿瘤类型等等。在这一步以及下面选择临床信息的这两步里,你会发现SEER数据库有许多自己定义的简写和缩写,比如mets at dx代表远处转移,转移部位和病理类型都用代号表示,刚开始看的时候有些二丈和尚摸不着头脑。
建议大家到上面那个官网下载“CS coding instructions”的文件,里面详细罗列了该数据库使用的每个coding的解释,但说明文件是全英文的,所以需要花点时间仔细看下。

第三栏是table,也就是选择你需要的临床信息。一定要记得(敲黑板!)右边sort 那一栏选择加入patient ID,这样你导出的所有病例都是按照ID号排序的,就不会混乱。
当然如果你需要按其他变量排序也是可以的。左边column那栏就选择你要的变量就行啦,这时候你会发现SEER的信息确实登记得非常全面,常用的年龄、病理类型、AJCC分期、生存时间、死因、治疗等等都有。
最后点击工具栏的闪电按钮(execute)就可以下载病例数据啦,最后出现的是表格形式,可以将表格的数据直接复制黏贴到excel里。SEER*stat软件自身也带有一些统计功能,但我自己习惯在SPSS里进行统计分析,大家也可以再摸索一下SEER的其他功能。
2、 初步数据分析
临床信息下载好以后还要根据研究目的进行数据分析,常用的无非是基线资料比较、单因素和多因素回归分析、生存分析、倾向性得分匹配(ps matching),森林图等等。
据说解螺旋读者们taste都比较高,不屑于看灌水文,所以笔者不好意思把拙作拿出来丢人,只好找了一篇IF相对较高的文章跟大家一起学习下这类文章的套路。
这是今年刚刚发表在JAMA Oncology(IF:16)上的文章:Brain Metastases in Newly Diagnosed Breast Cancer:A Population-Based Study(PMID:28301662)。全文大家可以自行下载。
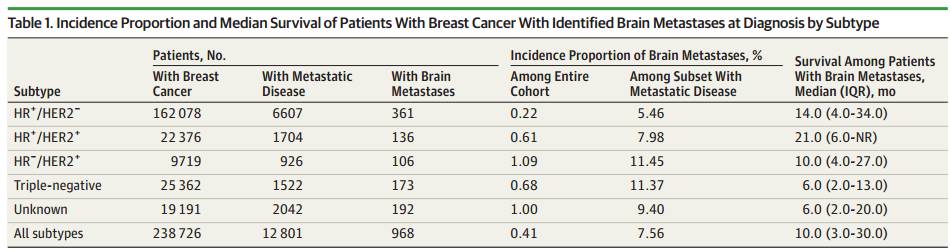
作者想要研究乳腺癌脑转移的发病率和预后。第一张表格按照分子分型统计了脑转移患者的发病率和中位生存时间。将数据导入到SPSS里后,选择分析→描述统计→交叉表格就可以统计每一类患者的例数,右边的中位生存时间可以在SEER里下载survival time自行统计。
第二张和第三张表格是多因素cox回归分析。先新建一栏,将还生存病例的命名为0,已死亡的命名为1。然后在SPSS里选择分析→生存函数→cox回归,时间选survival time,状态选刚才命名的数字。
然后选入你要分析的协变量,如果是分类变量,要再选择右边的“分类”按钮,添加为分类协变量,选择对比(reference)。再点选项按钮,勾选95%CI前的方框。
全部选好以后点OK,就完成啦!顺利的话,HR值,95%CI和P值在输出结果里全部都有。表三最右一栏的乳腺癌特异性死亡率也很简单,只要下载患者的死因信息(COD),把死于乳腺癌的患者命名为1,其余为0,后续操作相同。

第一张图是生存曲线,利用SPSS或者Graphpad里的survival功能都可以实现,不会的自行百度吧。
是不是有些羡慕嫉妒恨,为什么这么简单的文章就能发JAMA子刊?!说不定你也可以哦!