如果你退出 Python 解释器并重新进入,你做的任何定义(变量和方法)都会丢失。因此,如果你想要编写一些更大的程序,为准备解释器输入使用一个文本编辑器会更好,并以那个文件替代作为输入执行。这就是传说中的脚本。随着你的程序变得越来越长,你可能想要将它分割成几个更易于维护的文件。你也可能想在不同的程序中使用顺手的函数,而不是把代码在它们之间中拷来拷去。
为了满足这些需要,Python 提供了一个方法可以从文件中获取定义,在 脚本或者解释器的一个交互式实例中使用。这样的文件被称为模块;模块中的定义可以导入到另一个模块或主模块中(在脚本执行时可以调用的变量集位于最高级,并且处于计算器模式)。
模块是包括 Python 定义和声明的文件。文件名就是模块名加上 .py 后 。模块的模块名(作为一个字符串)可以由全局变量__name__ 得到。例如,你可以用自己惯用的文件编辑器在当前目录下创建一个叫 fifibo.py 的文件,录入如下内容:
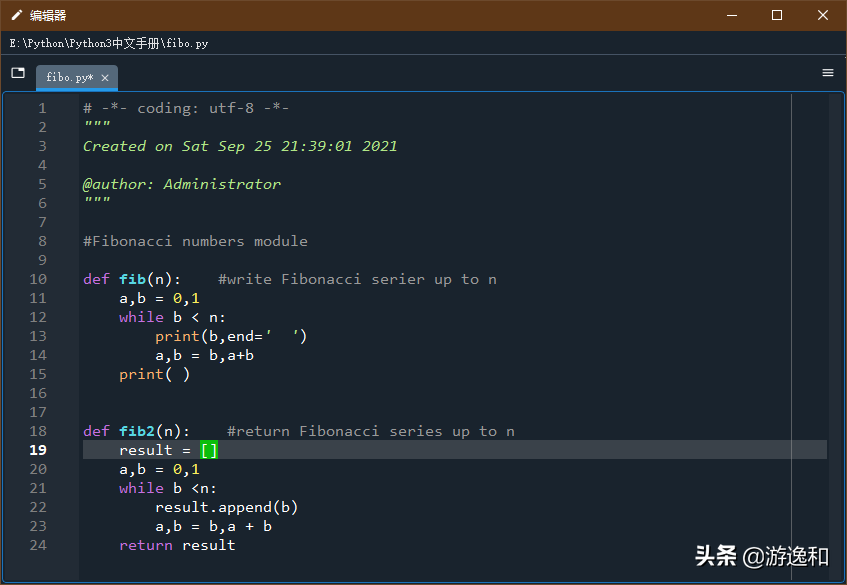
现在进入 Python 解释器并使用以下命令导入这个模块:
>>> import fibo
这样做不会直接把 fifibo 中的函数导入当前的语义表;它只是引入了模块名 fifibo。你可以通过模块名按如下方式访问这个函数。
>>> fibo.fib(1000) 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 >>> fibo.fib2(100) [1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89] >>> fibo.__name__ 'fibo'
如果打算频繁使用一个函数,你可以将它赋予一个本地变量:
>>> fib = fibo.fib >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
深入模块
除了包含函数定义外,模块也可以包含可执行语句。这些语句一般用来初始化模块。它们仅在第丬次被导入的地方执行一次 (事实上函数定义既是“声明”又是“可执行体”;执行体由函数在模块全局语义表中的命名导入)
每个模块都有自己私有的符号表,被模块内所有的函数定义作为全局符号表使用。因此,模块的作者可以在模块内部使用全局变量,而无需担心它与某个用户的全局变量意外冲突。从另一个方面讲,如果你确切地知道自己在做什么,你可以使用引用模块函数的表示法访问模块的全局变量。
模块可以导入其他的模块。一个好的习惯是将所有的 import 语句放在模 块或脚本的径始,这并非强制。被导入的模块名会放入当前模块的全局符号表中。
import 语句的一个变体直接从被导入的模块中导入命名到本模块的语义表中。例如:
>>> from fibo import fib,fib2 >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这样不会从局域语义表中导入模块名(如上所示,fibo 没有定义),甚至有种方式可以导入模块中的所有定义:
>>> from fibo import* >>> fib(500) 1 1 2 3 5 8 13 21 34 55 89 144 233 377
这样可以导入所有除了以下划线(‘_’)开头的命名。
需要注意的是在实践中往往不鼓励从一个模块或包中使用 * 导入所有, 因为这样会让代码变得很难读。不过,在交互式会话中这样用很方便省力。
Note
出于性能考虑, 每个模块在每个解释器会话中只导入乥遍。 因此,如果你修改了你的模块, 需要重启解释器; 或者, 如果你就是想交互式的测试这么一个模块, 可以用 imp.reload() 重新加载, 例如 import imp; imp.reload(modulename)。