前言:安装两个所用插件!
第一个:谷歌浏览器chromedriver!
第二个:phantomjs无界面浏览器(是基于webkit浏览器引擎的浏览器)!
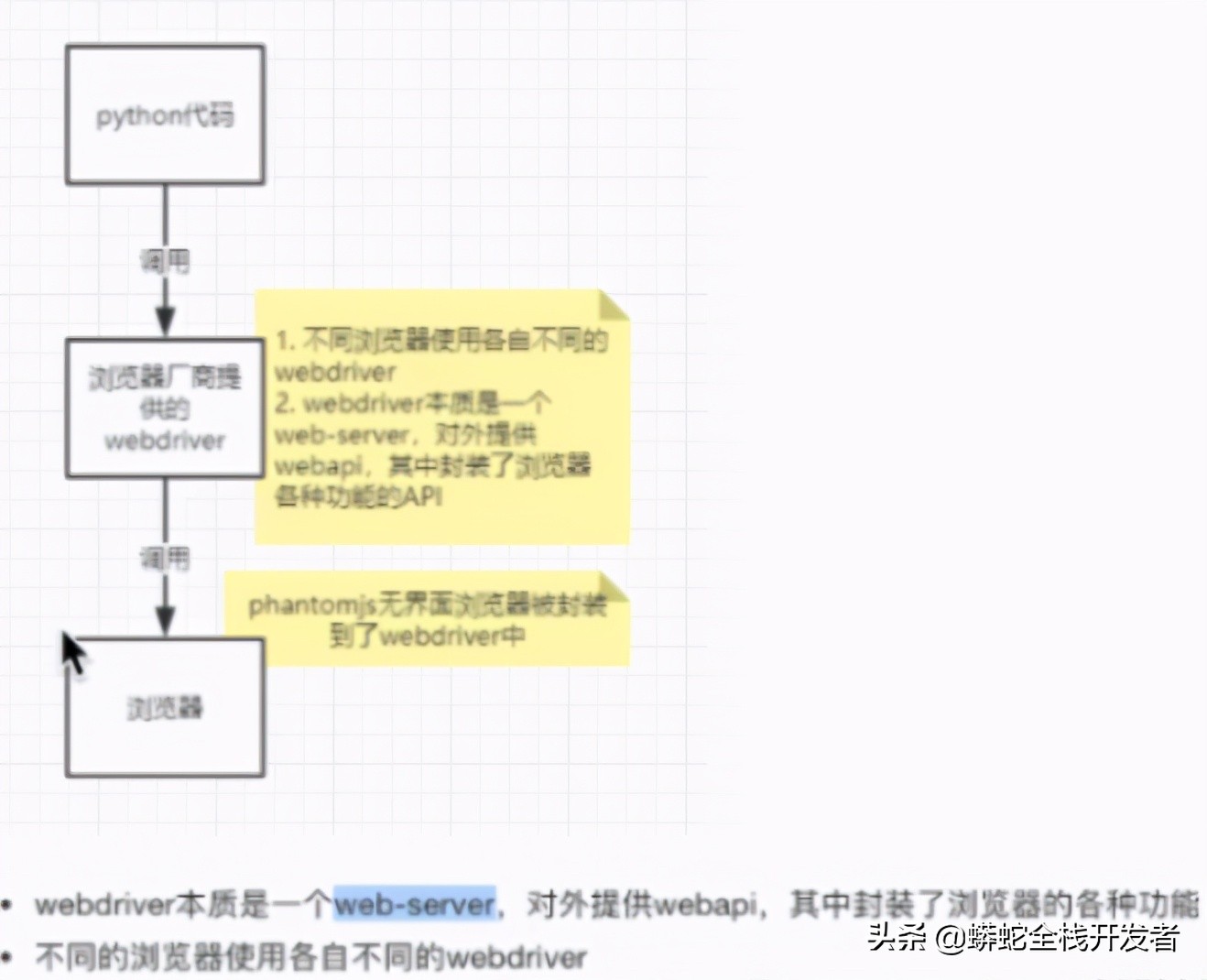
1.selenium的作用和工作原理
(开发使用有头浏览器,部署使用无界面浏览器)
1.selenium模块安装:
pip install seleniudriver浏览器引擎安装:
2.driver浏览器引擎安装:
安装driver(根据获取浏览器版本安装浏览器引擎)
步骤:
1. 获取当前浏览器版本(谷歌为例:帮助里面)
2. 访问:https://npm.taobao.org/mirrors/chromedriver 下载对应的driver版本
3. 解压,获取可执行文件
windows为chromedriver.exe
linux/mac为chromedriver
4. chromedriver环境配置
Windows环境下,需要将chromedriver.exe所在的目录设置为path环境变量中的路径
linux/mac环境下,将chromedriver所在的目录设置到系统的PATH环境值中
3.简单使用selenium:
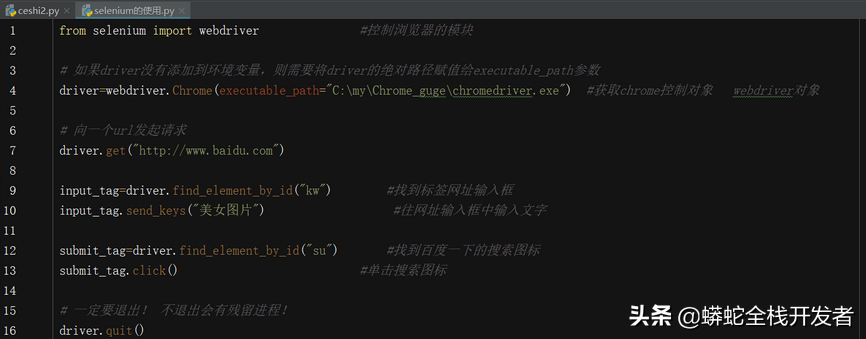
解析:
1.webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")中executable参数指定的是下载好的chromedriver文件路径
2.driver.find_element_by_id('kw').send_keys('美女图片')定位id属性值是‘kw’的标签,并向其中输入字符串‘美女图片’
3.driver.find_element_by_id('su').click()定位id属性值是su的标签,并点击click函数的作用是:触发标签的js的click事件
2.WebDriver操作浏览器的方式
# 最大化浏览器 driver.maximize_window() # 刷新 driver.refresh() # 后退 driver.back() # 前进 driver.forward() # 设置浏览器大小 driver.set_window_size(300,300) # 设置浏览器位置 driver.set_window_position(300,200) # 关闭浏览器单个窗口 driver.close() # 关闭浏览器所有窗口 driver.quit()
3.WebDriver其他常用方法
1. size 返回节点的大小,也就是宽高
2. text 获取元素的文本
3. title 获取页面title
4. current_url 获取当前页面URL
5. get_attribute("xxx") 获取属性值;xxx:要获取的属性
6. is_display() 判断元素是否可见
7. is_enabled() 判断元素是否可用
8. location 获取节点在页面中的相对位置
9. tag_name获取标签名称
提示:
10. size、text、title、current_url:为属性,调用时无括号;如:xxx.size
11. title、current_url:使用浏览器实例化对象直接调用; 如: driver.title
# 获取输入文本框大小
size=driver.find_element_by_id("userA").size
print('size:',size)
# 获取a标签内容
text=driver.find_element_by_id("fwA").text
print('a标签text:',text)
# 获取title
title=driver.title
print('title:',title)
# 获取当前页面url
url=driver.current_url
print('url:',url)
# 获取a标签href属性值
href=driver.find_element_by_id("fwA").get_attribute("href")
print('href属性值为:',href)
# 判断span是否显示
display=driver.find_element_by_css_selector('span').is_displayed()
print('span标签是否显示:',display)
# 判断取消按钮是否可用
enabled=driver.find_element_by_id('cancelA').is_enabled()
print('取消按钮是否可用:',enabled)
4.driver对象的常用属性和方法
driver.page_source当前标签页浏览器渲染之后的网页源代码
driver.current_url当前标签页的url
driver.close()关闭当前标签页,如果只有一个标签页则关闭整个浏览器
driver.quit()关闭浏览器
driver.forward()页面前进
driver.back()页面后退
driver.screen_shot(img_name)页面截图(现版本已移除此功能!)
实战:连续访问三个页面,然后调用back()方法回到第二个页面,接下来再调用forward()方法又可以前进到第三个页面!
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.get('https://taobao.com')
browser.get('https://www.python.org')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
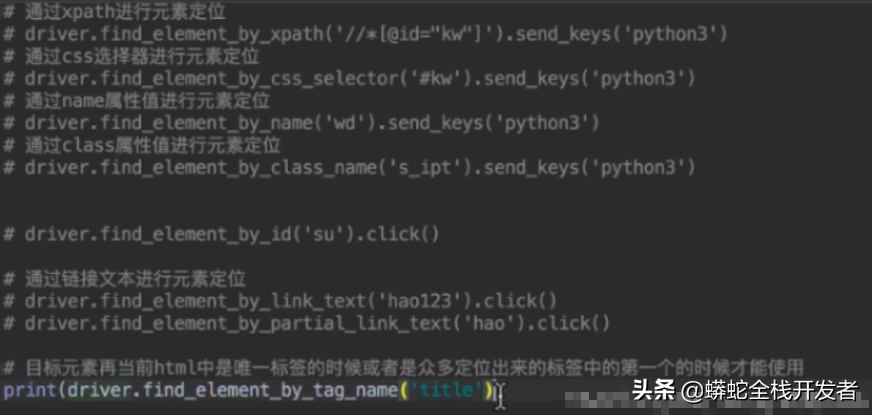
5.driver对象定位标签元素获取标签对象的方法
find_element_by_id返回一个元素
find_element(s)_by_class_name根据类名获取元素列表
find_element(s)_by_name根据标签的name属性值返回包含标签对象元素的列表
find_element(s)_by_xpath返回一个包含元素的列表
find_element(s)_by_link_text根据连接文本获取元素列表
find_element(s)_by_partial_link_text根据链接包含的文本获取元素列表
find_element(s)_by_tag_name根据标签名获取元素列表
find_element(s)_by_css_selector根据css选择器来获取元素列表
解析:
①find_element和find_elements的区别:
多了个s就返回列表,没有s就返回匹配到的第一个标签对象
find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
②by_link_text和by_partial_link_text的区别:全部文本和包含某个文本
③以上函数的使用方法:
driver.find_element_by_id('id_str')
6.WebDriver操作鼠标方法
1. context_click() 右击 --> 此方法模拟鼠标右键点击效果
2. double_click() 双击 --> 此方法模拟双标双击效果
3. drag_and_drop() 拖动 --> 此方法模拟双标拖动效果
4. move_to_element() 悬停 --> 此方法模拟鼠标悬停效果
5. perform() 执行 --> 此方法用来执行以上所有鼠标方法
示例:
1. 导包:from selenium.webdriver.common.action_chains import ActionChains
2. 实例化ActionChains对象:Action=ActionChains(driver)
3. 调用右键方法:element=Action.context_click(username)
4. 执行:element.perform()
示例:
# 定位用户名
element=driver.find_element_by_id("userA")
# 输入用户名
element.send_keys("admin1")
# 删除1
element.send_keys(Keys.BACK_SPACE)
# 全选
element.send_keys(Keys.CONTROL,'a')
# 复制
element.send_keys(Keys.CONTROL,'c')
# 粘贴
driver.find_element_by_id('passwordA').send_keys(Keys.CONTROL,'v')
7.标签对象提取文本内容和属性值
获取文本element.text:
通过定位获取的标签对象的 text 属性,获取文本内容
获取属性值 element.get_attribute('属性名'):
通过定位获取的标签对象的 get_attribute 函数,传入属性名,来获取属性的值
8.selenium控制标签页的切换
窗口切换:
获取所有标签页的窗口句柄
利用窗口句柄字切换到句柄指向的标签页
窗口句柄:指的是指向标签页对象的标识
解析:
#1.获取当前所有的标签页的句柄构成的列表
current_windows = driver.window_handles
#2.根据标签页句柄列表索引下标进行切换
driver.switch_to.window(windows[0])
代码使用:
import time
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('https://www.baidu.com/')
time.sleep(1)
driver.find_element_by_id('kw').send_keys('python')
time.sleep(1)
driver.find_element_by_id('su').click()
time.sleep(1)
# 通过执行js来新开一个标签页
js = "window.open('https://www.sougou.com');"
driver.execute_script(js)
time.sleep(1)
# 1.获取当前所有的窗口
windows = driver.window_handles
time.sleep(2)
# 2.根据窗口索引进行切换
driver.switch_to.window(windows[0])
time.sleep(2)
driver.switch_to.window(windows[1])
time.sleep(6)
driver.quit()
9.selenium控制iframe的切换
iframe是html中常用的一种技术,即一个页面中嵌套了另一个网页,selenium默认是访问不了frame中的内容的,对应的解决思路是driver.switch_to.frame(frame_element)。
第一部分:基操!
实际例子:进行QQ空间登录!
难点:无法解决登录过程中出现iframe,即此页面中嵌套了登录网页!
切换到定位的frame标签嵌套的页面中:
driver.switch_to.frame(通过find_element_by函数定位的frame、iframe标签对象)
import time
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('https://qzone.qq.com/')
time.sleep(2)
driver.switch_to.frame('login_frame') # 转向到登录frame中
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
# driver.find_element_by_id('u').send_keys('QQ号')
# 更保险的操作
driver.find_element_by_xpath('//*[@id="u"]').send_keys('QQ号')
driver.find_element_by_xpath('//*[@id="p"]').send_keys('密码')
driver.find_element_by_id('login_button').click()
# 小拓展:如何在F12中简单正确的获取定位想要元素的xpath语法:
# F12检查-->右击copy-->copy_xpath语法
driver.quit()
第二部分:骚操作!
1. 跳回最外层的页面
driver.switch_to.default_content() -- 切换到最外层(对于多层页面,可通过该方法直接切换到最外层)
2. 跳回上层的页面
driver.switch_to.parent_frame() -- 进行向上的单层切换
3.利用切换标签页的方式切出frame标签
windows = driver.window_handles
driver.switch_to.window(windows[0])
实际例子:进行QQ邮箱的登录操作以及frame标签的切出操作!
import time
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
url = 'https://mail.qq.com/cgi-bin/loginpage'
driver.get(url)
time.sleep(2)
login_frame = driver.find_element_by_id('login_frame') # 根据id定位frame元素
driver.switch_to.frame('login_frame') # 转向到登录frame中
driver.find_element_by_xpath('//*[@id="switcher_plogin"]').click()
driver.find_element_by_xpath('//*[@id="u"]').send_keys('QQ号@qq.com')
time.sleep(2)
driver.find_element_by_xpath('//*[@id="p"]').send_keys('密码')
time.sleep(2)
# driver.find_element_by_xpath('//*[@id="login_button"]').click()
# time.sleep(2)
"""操作frame外边的元素需要切换出去"""
windows = driver.window_handles
driver.switch_to.window(windows[0])
# 进行初始页面内元素的操作
content = driver.find_element_by_class_name('login_pictures_title').text
print(content)
# driver.quit()
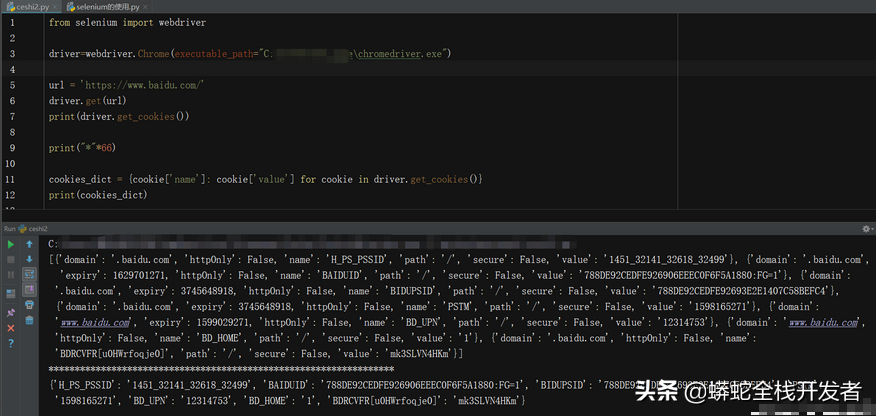
10.利用selenium获取cookie的方法
获取cookie:
driver.get_cookies() 返回列表,其中包含的是完整的cookie信息,需要转换为字典
字典推导式转换:
cookies_dict = {cookie['name']: cookie['value'] for cookie in driver.get_cookies()}
删除cookie:
①删除一条cookie:
driver.delete_cookie('cookie_name')
②删除所有的cookie:
driver.delete_all_cookies()
③添加一条cookie:
driver.add_cookie({'name': 'python', 'value': 'good'})
11.页面等待
分类:
1.强制等待
time.sleep()
缺点:不智能,设置的时间太短,元素还没有加载出来,设置的时间太长,浪费时间
2.隐式等待
针对元素定位,隐式等待设置了一个时间,在一段时间内判断元素是否定位成功,如果完成了,就进行下一步
在设置时间内没有定位成功,则会报超时加载
代码使用示例:通过隐式等待获取百度首页特定元素的属性!
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
url = 'https://www.baidu.com/'
# 设置之后的所有元素定位操作都有最大等待时间10S,在10S内会定期进行元素定位,超时则抛出找不到节点的异常
# 换句话说,当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0。
driver.implicitly_wait(10)
driver.get(url)
el = driver.find_element_by_xpath('//*[@id="lg"]/img[1]')
print(el)
3.显示等待
明确等待某一个元素,超时则报异常
代码使用示例:通过显示等待实现百度首页特定元素属性的获取!
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
url = 'https://www.baidu.com/'
driver.get(url)
# 显示等待
WebDriverWait(driver, 20, 0.5).until(
EC.presence_of_element_located(
(By.LINK_TEXT, 'hao123')
)
)
'''
参数20表示最长等待20S
参数0.5表示0.5S检查一次规定的标签是否存在
EC.presence_of_element_located(
(By.LINK_TEXT, 'hao123')
)
EC表示要等待的条件,此处传入了presence_of_element_located这个条件,代表节点出现的意思。
其参数是节点的定位元组,也就是链接文本内容为hao123的节点。
每0.5S检查一次,通过链接文本定位标签是否存在,如果存在就向下继续执行;
如果不存在,直到20S上限就报错
'''
content = driver.find_element_by_link_text('hao123').get_attribute('href')
print(content)
手动实现页面等待
原理:
利用强制等待和显示等待的思路来手动实现
不停的判断或有次数限制的判断某一个标签对象是否加载完毕(是否存在)
代码使用示例:实现通过淘宝网页自动向下滚动,以获取特定元素属性!
import time
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('https://www.taobao.com')
time.sleep(1)
for i in range(30):
i += 1
try:
time.sleep(3)
element = driver.find_element_by_xpath('/html/body/div[12]/div/div/h3')
result = element.text
print(result)
break
except:
# 网页滚动条的拖动
js = 'window.scrollTo(0,{})'.format(i * 500) # js语句
driver.execute_script(js) # 执行js的方法
driver.quit()
12.selenium控制浏览器执行js代码的方法
执行js的方法:driver.execute_script(js)
代码示例:网页滚动条的拖动!
from selenium import webdriver
driver=webdriver.Chrome(executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('https://www.taobao.com')
# 网页滚动条的拖动
js = 'scrollTo(0,1220)' # js语句
driver.execute_script(js) # 执行js的方法
driver.quit()
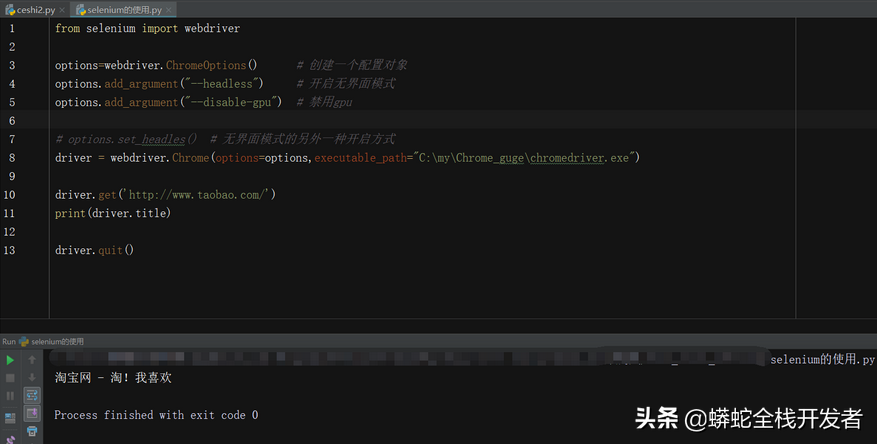
13.selenium开启无界面模式(无头模式)
开启无界面模式的方法:
①创建一个配置对象
options = webdriver.ChromeOptions()
②配置对象添加开启无界面模式的命令
options.add_argument("--headless")
③配置对象添加禁用gpu的命令
options.add_argument("--disable-gpu")
④实例化带有配置对象的driver对象
driver = webdriver.Chrome(options=options,executable_path="C:\my\Chrome_guge\chromedriver.exe")
注意:macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式!
14.selenium使用代理IP
使用代理ip的方法:
①创建一个配置对象
options = webdriver.ChromeOptions()
②配置对象添加使用代理ip的命令
options.add_argument('--proxy-server=http://202.20.16.82:9527')
③实例化带有配置对象的driver对象
driver = webdriver.Chrome(options=options,executable_path="C:\my\Chrome_guge\chromedriver.exe")
from selenium import webdriver
options=webdriver.ChromeOptions() # 创建一个配置对象
options.add_argument('--proxy-server=http://202.20.16.82:9527') # 使用代理ip
driver = webdriver.Chrome(options=options,executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('http://www.taobao.com/')
print(driver.title)
driver.quit()
15.selenium替换user-agent
替换user-agent的方法
①创建一个配置对象
options = webdriver.ChromeOptions()
②配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA')
③实例化带有配置对象的driver对象
driver = webdriver.Chrome(options=options,executable_path="C:\my\Chrome_guge\chromedriver.exe")
from selenium import webdriver
options=webdriver.ChromeOptions() # 创建一个配置对象
# 配置对象添加替换UA的命令
options.add_argument('--user-agent=Mozilla/5.0 HAHA') # 替换user-agent
# 实例化带有配置对象的driver对象
driver = webdriver.Chrome(options=options,executable_path="C:\my\Chrome_guge\chromedriver.exe")
driver.get('http://www.taobao.com/')
print(driver.title)
driver.quit()
16.选项卡管理
首先访问百度,然后调用execute_script()方法传入window.open()这个JavaScript语句新开启一个选项卡。
接下来切换到选项卡,在选项卡下打开一个新页面,然后切换回第一个选项卡访问东!
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to.window(browser.window_handles[0])
browser.get('https://www.jd.com/')
17.异常处理
在使用selenium过程中,难免遇到一些异常,例如超时,节点未找到等错误,一旦出现程序便中断,这里我们使用try except语句来捕获各种异常!
from selenium import webdriver
from selenium.common.exceptions import TimeoutException, NoSuchElementException
browser = webdriver.Chrome()
try:
browser.get('https://www.baidu.com')
except TimeoutException:
print('Time Out!')
try:
browser.find_element_by_id('hello')
except NoSuchElementException:
print('No Element!')
finally:
browser.close()
18.selenium中一些实用的操作
①两种点击操作:
from selenium.webdriver.common.keys import Keys # 假设input为定位到的需要点击操作的标签。 # 下面的操作效果同input.click()一样! input.send_keys(Keys.ENTER)
②定位不到元素异常的捕获:
from selenium.common.exceptions import NoSuchElementException
# 以下捕获异常的方法可以避免元素定位不到而报错!
try:
# 假设browser为初始化的浏览器对象
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('No find logo!')