概述
在分布式系统中,我们广泛运用消息中间件进行系统间的数据交换,便于异步解耦。现在开源的消息中间件有很多,前段时间产品 RocketMQ (MetaQ的内核) 也顺利开源。不过今天主要是对Kafka与RabbitMQ功能做个对比。
MQ简介
MQ,Message queue,消息队列,就是指保存消息的一个容器。具体的定义这里就不类似于数据库、缓存等,用来保存数据的。当然,与数据库、缓存等产品比较,也有自己一些特点。
现在常用的MQ组件有ActiveMQ、RabbitMQ、RocketMQ、ZeroMQ、MetaMQ,当然近年来火热的kafka,从某些场景来说,也是MQ,当然kafka的功能更加强大,虽然不同的MQ都有自己的特点和优势,但是,不管是哪种MQ,都有MQ本身自带的一些特点,下面,介绍MQ的特点。
MQ特点
1、先进先出
不能先进先出,都不能说是队列了。消息队列的顺序在入队的时候就基本已经确定了,一般是不需人工干预的。而且,最重要的是,数据是只有一条数据在使用中。 这也是MQ在诸多场景被使用的原因。
2、发布订阅
发布订阅是一种很高效的处理方式,如果不发生阻塞,基本可以当做是同步操作。这种处理方式能非常有效的提升服务器利用率,这样的应用场景非常广泛。
3、持久化
持久化确保MQ的使用不只是一个部分场景的辅助工具,而是让MQ能像数据库一样存储核心的数据。
4、分布式
在现在大流量、大数据的使用场景下,只支持单体应用的服务器软件基本是无法使用的,支持分布式的部署,才能被广泛使用。而且,MQ的定位就是一个高性能的中间件。
Kafka和RabbitMQ
下面主要对常见的两类消息产品(Kafka、RabbitMQ)做一下介绍。
1、Kafka
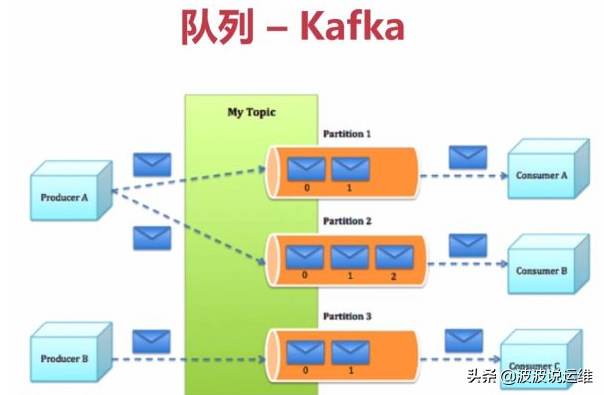
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,适合产生大量数据的互联网服务的数据收集业务。
2、RabbitMQ
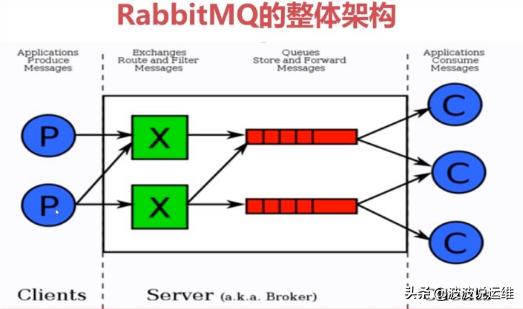
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
区别
下表是对Kafka与RabbitMQ功能的总结性对比及补充说明
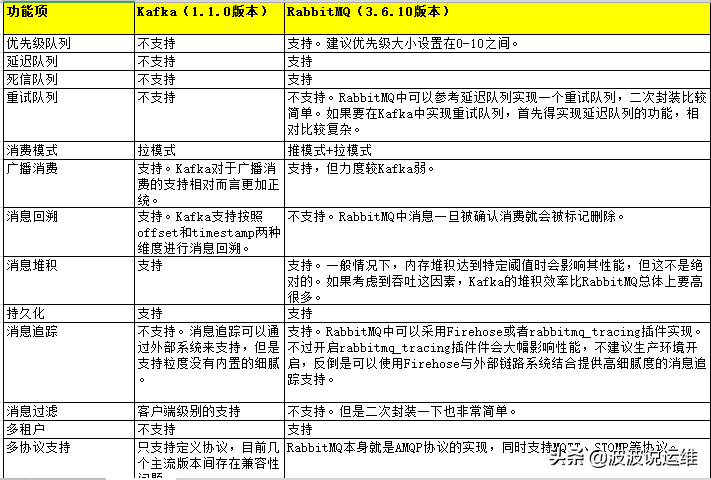
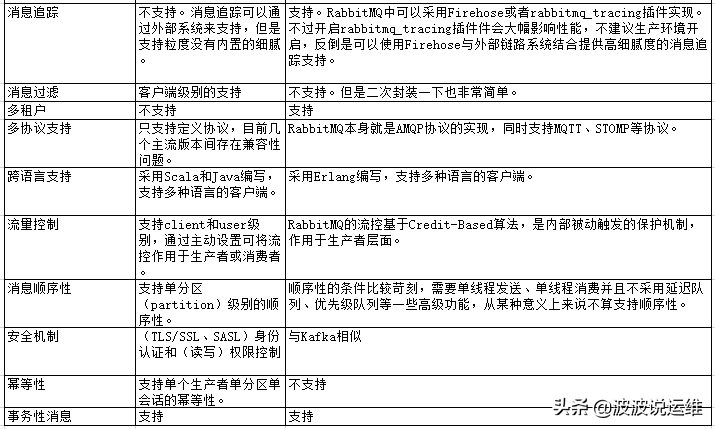

Rabbitmq比kafka可靠,kafka更适合IO高吞吐的处理,比如ELK日志收集
Kafka和RabbitMq一样是通用意图消息代理,他们都是以分布式部署为目的。但是他们对消息语义模型的定义的假设是非常不同的。
a) 以下场景比较适合使用Kafka。如果有大量的事件(10万以上/秒)、你需要以分区的,顺序的,至少传递成功一次到混杂了在线和打包消费的消费者、希望能重读消息、你能接受目前是有限的节点级别高可用就可以考虑kafka。
b) 以下场景比较适合使用RabbitMQ。如果是较少的事件(2万以上/秒)并且需要通过复杂的路由逻辑去找到消费者、你希望消息传递是可靠的、并不关心消息传递的顺序、而且需要现在就支持集群-节点级别的高可用就可以考虑rabbitmq。