1.建表:
1)常规建表:
create table temp_1( Tempcode varchar2(30) not null, TempName varchar2(15) );
创建字段为TempCode,TempName的temp_1表,新创建的表中无数据,如下图所示:
2)根据查询结果建表:
create table temp_1 as select tempcode,tempname from temp_2;
创建字段为TempCode,TempName的temp_1表,新创建的表中存在temp_2的存储结果,如下图所示:

3)创建事务级临时表:
create global temporary table temp_1( Tempcode varchar2(30) not null, TempName varchar2(15) ) on commit delete rows
创建字段为TempCode,TempName的temp_1表,新创建的表为事务级临时表,当该表事务进行提交commit/回滚rollback时,清除表内所有数据(truncate)
4)创建会话级临时表:
create global temporary table temp_1( Tempcode varchar2(30) not null, TempName varchar2(15) ) on commit preserve rows
创建字段为TempCode,TempName的temp_1表,新创建的表为会话级临时表,当会话结束时,清除表内所有数据(truncate)
2.新增
1)单行插入
insert into temp_1(tempcode) values('1001'); --指定字段插入
insert into temp_1 values('1001','张三同学'); --全字段插入
执行insert操作,如下图所示:

2)根据查询结果插入
insert into temp_1(tempcode) select tempcode from temp_2; --指定字段插入 insert into temp_1 select tempcode,tempname from temp_2; --全字段插入
指定字段插入,如下图所示:
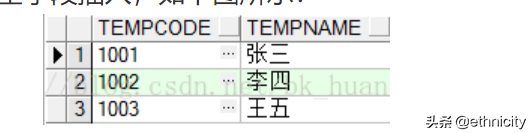
全字段插入,如下图所示:
3.删除
1)delete:删除表数据,不删除表结构,事务提交后删除,DML语句,不释放表空间,激活触发器
2)truncate:删除表数据,不删除表结构,执行后自动提交,DDL语句,保留原始表空间,不激活触发器
(外键约束引用的表和参与视图索引的表不能使用truncate)
3)drop:删除表数据、表结构等,DDL语句,释放表空间,删除触发器
性能比较:drop>truncate>delete
4.更新
1)单列更新
update temp_1 set tempname='张三(new)' where tempcode='1001'; --单列更新
2)多列更新
update temp_1 set tempname='李四(new)',tempcode='1002new' where tempcode='1002'; --多列更新
3)根据查询结果更新
update temp_1 set(tempname,tempcode) = (select tempname,tempcode from temp_2 where tempcode='1003new') where tempcode='1003'; --根据查询结果更新
执行更新操作后,结果如下图所示:

4)Merge into
merge into temp_1 a using (select tempcode code,tempname name from temp_2 where tempcode='1001') b on (a.tempcode = b.code) when matched then update set a.tempname = b.name when not matched then insert (tempcode, tempname) values (b.code, b.name)
条件满足,tempcode='1001'时,执行update操作;
把tempcode='1001'换成tempcode='1004',条件不满足,执行insert操作;
结果如下图所示:

5.完整的查询SQL语句格式:
select <查询结果集>
from <被查询表集>
where <查询条件集>
group by <分组条件集>
having <分组结果过滤>
order by <查询结果过滤>
6.连接
1)交叉连接:笛卡尔集 全连接
select * from temp_1 cross join temp_3; select * from temp_1,temp_3;

2)内连接:对于不匹配的都会进行舍弃
select * from temp_1 inner join temp_3 on temp_1.tempcode=temp_3.tempcode3; select * from temp_1,temp_3 where temp_1.tempcode=temp_3.tempcode3;

3)全外连接:左右无都补null
select * from temp_1 full join temp_3 on temp_1.tempcode=temp_3.tempcode3;
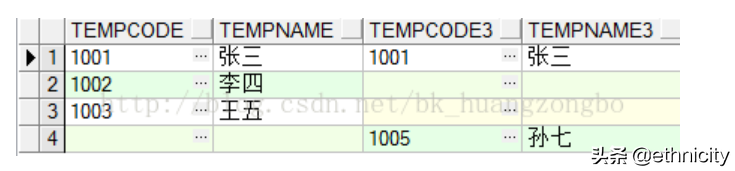
4)左外连接:左为基表,右表无则补null
select * from temp_1 left join temp_3 on temp_1.tempcode=temp_3.tempcode3;

5)右外连接:右为基表,左表无则补null
select * from temp_1 right join temp_3 on temp_1.tempcode=temp_3.tempcode3;
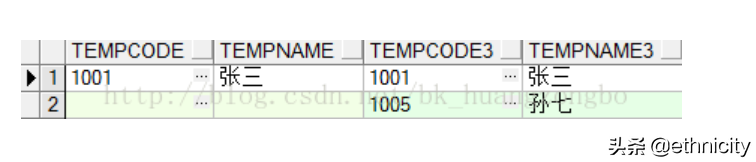
7.集合
1)union all:求并集,记录可以重复,不自动排序
select * from temp_1 where tempcode='1001' union all select * from temp_2 where tempcode='1001'
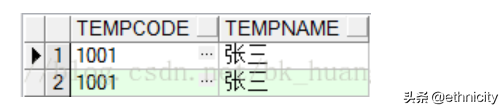
2)union:求并集,排除重复数据,自动排序
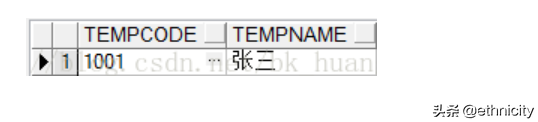
select * from temp_1 where tempcode='1001' union select * from temp_2 where tempcode='1001'

3)minus:求差集,自动排序
select * from temp_1 where tempcode in('1001','1002')
minus
select * from temp_2 where tempcode='1001'

4)intersect:求交集,自动排序
select * from temp_1 where tempcode in('1001','1002')
intersect
select * from temp_2 where tempcode='1001'
8.排序
1)order by
select * from temp_1 order by tempcode asc; --正序 asc可省略 select * from temp_1 order by tempcode desc; --倒序 desc不可省略
倒序结果如下图所示:

2)排名函数
rank()/dense_rank()/row_number() over(partition by 分组条件 order by 排序条件)
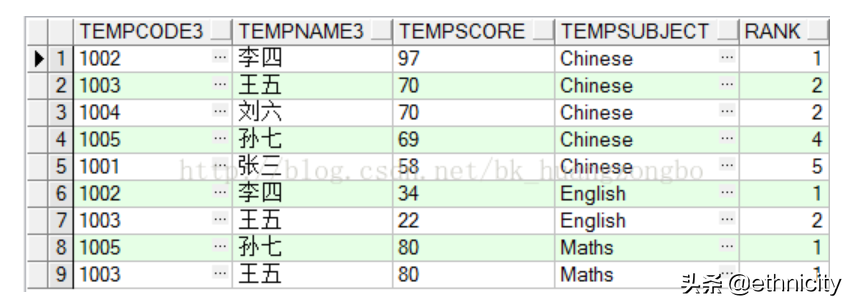
[1] rank() over: 进行排序,会跳过空出的名次,如(1,2,2,4,5)
select
tempcode3,
tempname3,
tempscore,
tempsubject,
rank() over(partition by tempsubject order by tempscore desc) as rank
from temp_4
按tempsubject学科分组,按tempscore成绩倒序排列,结果如下图所示:
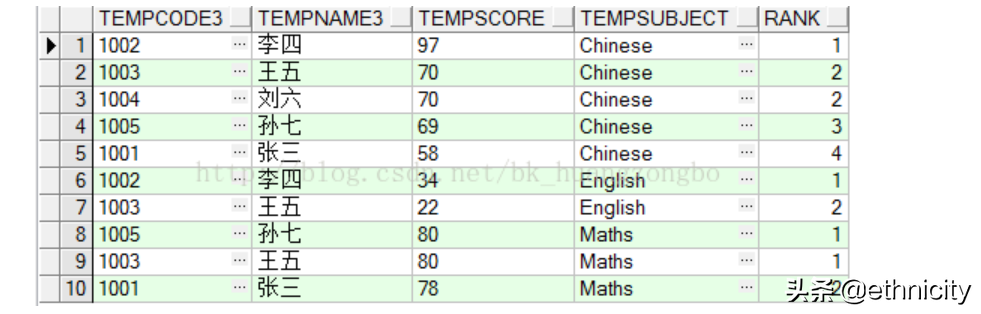
[2] dense_rank() over:进行排序,不会跳过空出的名次,如(1,2,2,3,4)
select
tempcode3,
tempname3,
tempscore,
tempsubject,
dense_rank() over(partition by tempsubject order by tempscore desc) as rank
from temp_4
按tempsubject学科分组,按tempscore成绩倒序排列,结果如下图所示:
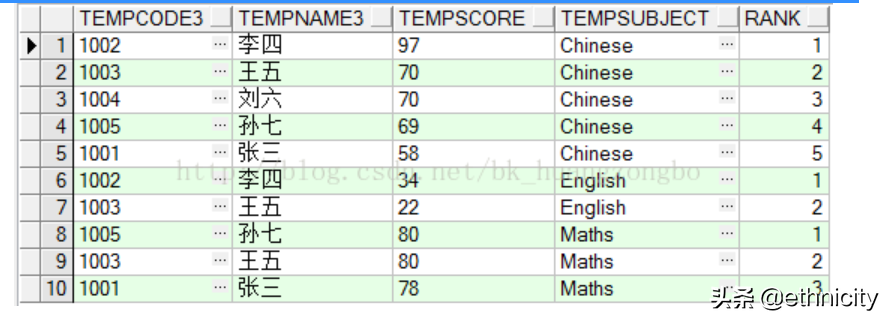
[3] row_number() over:进行排序,不会考虑成绩是否相同,即使相同也会继续排序,如(1,2,3,4,5)
select
tempcode3,
tempname3,
tempscore,
tempsubject,
row_number() over(partition by tempsubject order by tempscore desc) as rank
from temp_4
按tempsubject学科分组,按tempscore成绩倒序排列,结果如下图所示:
9.常用函数
1)字符函数
select
substr('abcdef', 1, 3) 截取,
length('abcdef') 长度,
instr('abcdabebc', 'a') 第一次出现的位置,
ltrim(' abc') 去除前空格,
rtrim('abc ') 去除后空格,
trim(' abc ') 去除前后空格
from dual;
查询结果如下图所示:

select
trim(leading 'd' from 'dabc') 去除前导,
trim(trailing 'd' from 'abcd') 去除后缀,
trim('d' from 'dabcd') 去除前后缀,
initcap('abc') 首字母大写,
upper('abc') 大写,
lower('ABC') 小写,
lpad('1', '3', '0') 向左填充0直到3位为止,
rpad('1', '3', '0') 向右填充0直到3位为止
from dual;
查询结果如下图所示:

2)数字函数
select
ceil(45.67) 向上取整,
floor(45.67) 向下取整,
round(45.678, 2) 四舍五入,
trunc(45.678, 2) 截断,
power(2, 10) 求幂,
mod(10, 3) 求余
from dual;
查询结果如下图所示:

3)日期函数
select
floor(sysdate - to_date('20171201', 'yyyy-MM-dd')) 相差天数,
months_between(sysdate, to_date('20171004', 'yyyy-MM-dd')) 相差月数,
add_months(sysdate, 2) 日期加2个月,
last_day(sysdate) 月末最后一天
from dual;
查询结果如下图所示:

select
round(sysdate) 舍入到最近一天,
round(sysdate, 'year') 舍入到最近年的1月1日,
round(sysdate, 'month') 舍入到最近月的1日,
trunc(sysdate) 截断到最近当天,
trunc(sysdate, 'year') 截断到最近年的1月1日,
trunc(sysdate, 'month') 截断到最近月的1日
from dual;
查询结果如下图所示:

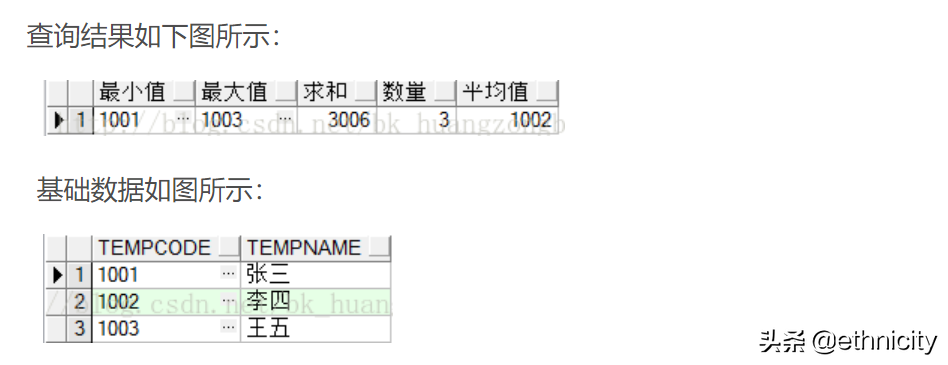
4)分组函数
select
min(tempcode) 最小值,
max(tempcode) 最大值,
sum(tempcode) 求和,
count(tempcode) 数量,
avg(tempcode) 平均值
from temp_1;
5)转换函数
[1] 日期格式转字符串
select
to_char(sysdate, 'yyyy-mm-dd hh24:mi:ss') 年月日时分秒,
to_char(sysdate, 'yyyymm') 年月,
to_char(sysdate, 'yyyy') 年,
to_char(sysdate, 'mm') 月,
to_char(sysdate, 'dd') 日,
to_char(sysdate, 'hh24') 时,
to_char(sysdate, 'mi') 分,
to_char(sysdate, 'ss') 秒,
to_char(sysdate, 'day') 星期
from dual;

[2] 字符串转日期格式
select
to_date('2017-12-04 17:19:54', 'yyyy-mm-dd hh24:mi:ss') 年月日时分秒,
to_date('2017-12-04', 'yyyy-mm-dd') 年月日,
to_date('201712', 'yyyymm') 年月
from dual;
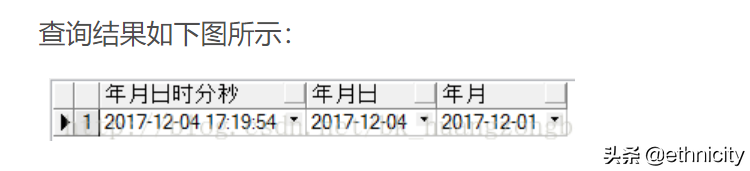
[3] 字符串转数字格式
select to_number('213.456') from dual;

6)其他函数
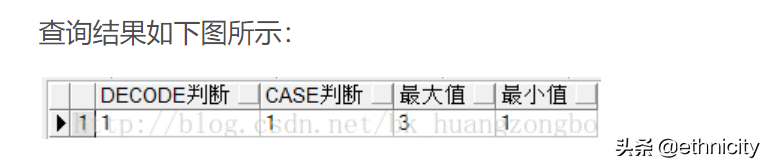
select
decode('a', 'a', '1', 'b', '2') decode判断,
case when 1 = 1 then '1' else '2' end case判断,
greatest('1', '2', '3') 最大值,
least('1', '2', '3') 最小值
from dual;