本次内容将分为四个部分为大家讲解:Hadoop简介、Hadoop的特点、Hadoop1.0与2.0的区别、Hadoop生态系统的组成。
1. Hadoop简介
说到hadoop不得不提起一个人——Doug Cutting,他是hadoop之父、Apache Lucene的创始人。
Hadoop是Apache旗下的开源的分布式计算平台,它可以运行在计算机集群之上,提供可靠的、可扩展的分布式计算功能。Hadoop的核心是分布式文件系统(HDFS)和并行编程框架MapReduce。
Hadoop与三遍论文密不可分:
① 2003年,谷歌发布的分布式文件系统GFS的论文,可以用于解决海量数据存储的问题。
② 2004年,谷歌发布了MapReduce的论文,可以用于解决海量数据计算的问题。
③ 2006年,谷歌发布了BigTable的论文,它是以GFS为底层数据存储的分布式存储系统。
|
年份 |
谷歌 |
|
2003年 |
谷歌分布式文件系统GFS的论文 |
|
2004年 |
谷歌MapReduce的论文 |
|
2006年 |
谷歌BigTable的论文 |
GFS、MapReduce、BigTable就是我们经常说的“三辆马车”。
Hadoop与这三篇论文的关系是这样的:
Hadoop中的HDFS是GFS的开源实现;Hadoop中的MapReduce是谷歌MapReduce的开源实现;Hadoop中的HBase是谷歌BigTable的开源实现。
2. hadoop的特点
① 跨平台性:hadoop是基于java语言开发的,有很好的跨平台性,可以运行在Linux平台上;
② 高可靠性:hadoop中的HDFS是分布式文件系统,可以将海量数据分布冗余存储在不同的机器节点上,即使是某个机器副本上发生故障,其他的机器副本也能正常运行;
③ 高容错性:HDFS把把文件分布存储在很多不同的机器节点上,能实现自动保存多个副本,因此某个节点上的任务失败后也能实现自动重新分配;
④ 高效性:hadoop的核心组件HDFS和MapReduce,一个负责分布式存储一个负责分布式处理,能够处理PB级别的数据;
⑤ 低成本与高扩展:hadoop在廉价的计算机集群上就可以运行,因此成本比较低,并且可以扩展到几千个计算机节点上,完成海量数据的存储和计算。
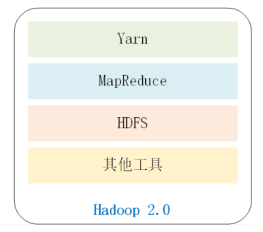
3. Hadoop1.0和2.0的区别
Hadoop1.0与2.0的最大区别就是,hadoop2.0在1.0的基础上增加了一个yarn框架。
① Hadoop1.0的组成包含:hdfs、MapReduce和其他组件。
Hdfs负责数据存储,MapReduce负责数据计算以及资源调度(在进行数据处理的时候是要进行资源分配的,比如用多少CPU、内存、磁盘等等)

② Hadoop2.0的组成包含:hdfs、MapReduce、yarn和其他组件。
Hdfs负责数据存储,MapReduce负责数据计算,yarn负责资源调度
4. Hadoop生态系统的组成
Hadoop除了有两大核心组件HDFS 和MapReduce之外,还包括yarn、hbase、hive、pig、mahout、zookeeper、sqoop、flume、Apache Ambari等功能组件。
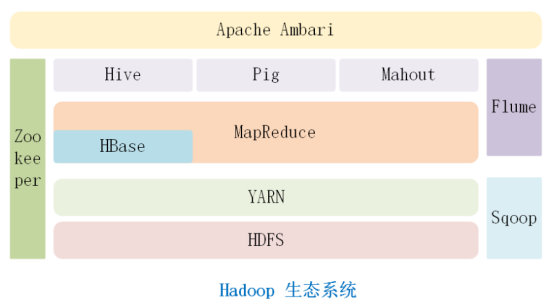
① HDFS:hadoop分布式文件系统,可以运行在大型的廉价计算机集群上,并以流的方式读取和处理海量文件。HDFS要掌握的概念有NameNode、DataNode和Secondary Namenode,后面会有专门章节为大家讲解。
② Yarn:资源调度和管理框架,其中包含ResourceManager、ApplicationMaster和NodeManager。ResourceManager负责资源管理,ApplicationMaster负责任务调度和监控,NodeManager 负责执行任务。
③ MapReduce:分布式并行编程框架,核心思想是“分而治之”。MapReduce=Map+Reduce。Map函数负责分片的工作,reduce函数负责整合归约。
④ HBase:是谷歌bigtable的开源实现。它区别于传统关系数据库的一点是:基于列式存储。传统数据库是基于行的存储,而HBase是基于列的存储,具有高效可靠的处理非结构化数据的能力。
⑤ Hive:是基于hadoop的数据仓库工具,能对数据集进行简单处理,它拥有类似SQL语言的查询语言hive-sql。
⑥ Pig:是一种数据流语言,提供了类似sql的语言pig latin,可以用来查询半结构化数据集。
⑦ Mahout:是Apache的一个开源项目,提供一些分类、聚类、过滤等等机器学习领域经典算法。
⑧ Zookeeper:是个高效的可靠的分布式协同工作系统。
⑨ Sqoop:sql-to-hadoop的缩写,意思就是在关系数据库与hadoop之间做数据交换。
⑩ Flume:海量日志收集、聚合、传输系统。它也能对数据进行简单的处理。
⑪ Apache Ambari:是一种支持Apache Hadoop集群的安装、部署、配置和管理的工具。