对于直播业务,";秒开、卡顿、延迟、入房成功率";是我们经常关注的几个指标,可以说是从";用户可以优雅地进入直播间";从角度考虑,但进入直播间后";用户看到了什么?";这也是一个关键环节。除了一些安全指标外,还可能有其他异常内容,如花屏和绿屏。此时,我们将考虑如何测量和发现外部网络的花屏。
本文主要以花屏为基础CNN网络检测方案。
本文主要以花屏为基础CNN网络检测方案。
01
构建花屏检测能力视频和直播都是由帧帧图像组成的。它们之所以以以动态的形式展现在我们面前,是因为人类的视觉暂留。
当物体快速运动时, 当人眼看到的图像消失时,人眼仍然可以保留其图像0.1-0.大约4秒的图像,这种现象被称为视觉暂留现象。
在这种情况下,检测直播中是否存在花屏,实际上可以转换为检测直播中的帧画面是否是花屏画面,即图像识别问题。那么如何识别图像是否是花屏呢?
通常,图像识别总是基于特征。我们将首先根据设定的目标提取相应的特征,以便以后制定策略。幸运的是,目前的深度学习卷积神经网络CNN帮助我们完成提取特征和制定决策策略。并运用深度学习CNN网络绕不开数据集
和模型训练两大块
1.1数据集准备
困难
使用深度学习网络,一个阈值需要足够的标签数据集,否则**学习网络容易过拟合,泛化能力不强。**这是因为实际业务中缺乏数据集的门槛。以目前的花屏为例。目前直播中花屏的案例很少,很难通过实际案例收集足够的花屏图片作为培训集。**这是一个门槛,因为实际业务中缺乏数据集。以目前的花屏为例。目前直播中花屏的案例很少,很难通过实际案例收集足够的花屏图片作为培训集。因此,我们必须探索其他收集培训集的方法。人类之所以能区分花屏,是因为人类的眼睛能找到花屏图像的特征,虽然我们可能无法用语言描述这些特征。事实上,如果我们能用语言描述特征,我们很容易将其翻译成代码来找到花屏图像的特征。
制作训练集
事实上,机器学习也是通过特征工作的。在这种情况下,我们可以制作一些花屏图像,让它们出来CNN网络发现它们不同于正常图片,从而学习花屏图片的检测能力。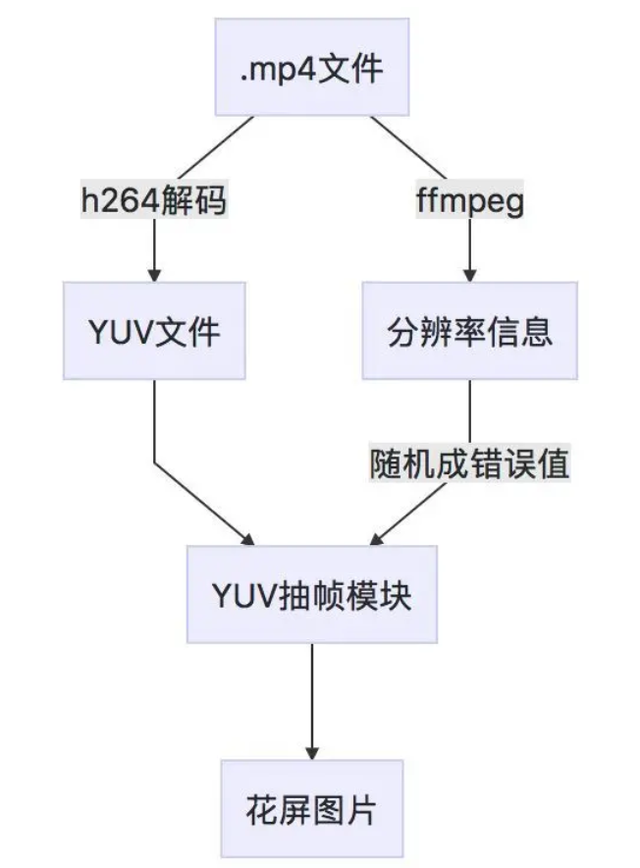
在使用YUVviewer当设置错误的分辨率来播放视频文件时,会发现花屏。灵感来自于此,我们可以使用错误的分辨率YUV从文件中提取帧,以获得花屏图片。整体流程如下:
这里需要了解YUV文件的存储格式,以便根据格式提取相应的帧:YUV,分为三个分量,Y表示亮度(Luminance或Luma),也就是灰度值;而U”和“V” 表示色度(Chrominance或Chroma),用于指定像素的颜色,描述图像颜色和饱和度。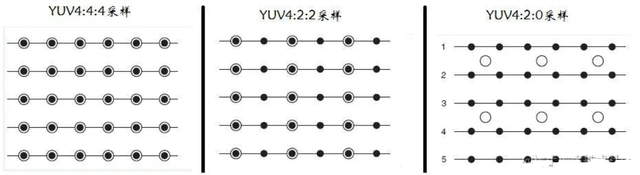
YUV采样风格有几种,用黑点代表采样像素点的Y分量,用空心圆圈代表采样像素点UV一般来说,我们使用重量YUV420格式

YUV420格式存储方式如下:
编写代码以上存储方式提取帧,代码如下:
def get_frames_from_YUV(filename, dims, numfrm, startfrm, frmstep): """ 从给定的YUV从文件中提取相应的帧数据,帧数据格式仍然是YUV :param filename: YUV文件路径 :param dims: YUV文件分辨率 :param numfrm: 提取帧数 :param startfrm: 从哪一帧开始提取 :param frmstep: 提取帧间隔,也就是每隔几帧抽一帧 :return: 返回提取帧的Y列表,U列表,V列表 """ filesize = os.path.getsize(filename) fp = open(filename, 'rb') blk_size = prod(dims) * 3 / 2 # 计算每帧大小 if (startfrm 1 (numfrm-1)*frmstep)*blk_size > filesize: numfrm = (filesize/blk_size - 1 - startfrm)/frmstep 1 util.log('.文件读取越界-修改%d'%numfrm) fp.seek(blk_size * startfrm, 0) # 跳转到指定的开始帧 Y, U, V=[],[]d00 = dims[0]/ 2 d01 = dims[1]/ 2 for i in range(numfrm): util.log(';文件文件的%;d帧' % i) Yt = zeros((dims[1], dims[0]), uint8, 'C') Ut = zeros((d01, d00), uint8, 'C') Vt = zeros((d01, d00), uint8, 'C') for m in range(dims[1]): for n in range(dims[0]): # print m,n Yt[m, n]= ord(fp.read(1)) for m in range(d01): for n in range(d00): Ut[m, n]= ord(fp.read(1)) for m in range(d01): for n in range(d00): Vt[m, n]= ord(fp.read(1)) Y = Y[Yt]U = U[Ut]V = V[Vt]fp.seek(blk_size * (frmstep - 1), 1) # 跳出间隔帧 fp.close() return (Y, U, V)
这里还研究了各种分辨率错误的情况,发现以下规则:
1)分辨率正确

2)分辨率width 1情况

3)分辨率width n情况

4)分辨率width-1情况

5)分辨率width-n情况
以上只是对图片宽度的错误干扰,可见宽变小花屏条纹方向是左下,宽变大花屏条纹方向是右下。因此,我们的团队宽度和高度分别设置不同的错误值,这将导致不同类型的花屏,因此我们可以使用这种策略来构建大量的花屏。
因此,我们的团队宽度和高度分别设置不同的错误值,这将导致不同类型的花屏,因此我们可以使用这种策略来构建大量的花屏。
 我们使用了800多个视频,每个视频在一定间隔内画出10帧,获得了8000多张花屏图片。
我们使用了800多个视频,每个视频在一定间隔内画出10帧,获得了8000多张花屏图片。这些图片为花屏,即我们的正样本,负样本可在实际直播中选择正常截图。
到目前为止,数据集的准备几乎是一样的。
1.2 模型和训练
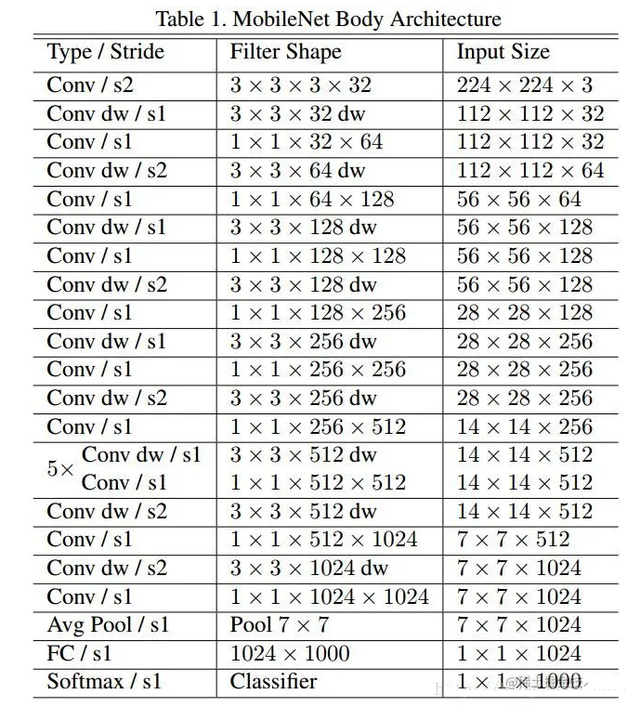
在模型上使用一些在线知名模型,我们在这里使用轻量级模型mobilenet模型,模型结构如下图所示:
基于训练imagenet训练好的模型来进行finetune训练的最后一层使用随机超参数进行训练(这一层不能读取pretrained由于分类数不一致,模型的超参数。训练可以快速收敛,因为特征太明显,测试集的准确性很高。训练可以快速收敛,因为特征太明显,测试集的准确性很高。事实上,这里的训练是一个不断迭代的过程,因为机器学习模型是一张白纸。你应该教它什么样的能力?教学方法是通过培训集(数据和标签)。如果你想让它处理更多的情况,你的培训集应该尽可能涵盖各种情况。我们的训练集总是不够的,你总是有的care不见的地方。训练集不足会怎么样?举个例子你训练一个识别飞机的模型,大多数关于飞机的图片都有天空,所以当你把天空的图片给模型时,它也可能被认为是一架飞机,因为事实上,模型可能会学习天空的特征。当然,如何让模型学习飞机的特点,需要调整训练集,这样训练集不仅包括背景为天空的飞机,还包括陆地上的飞机。通过不断的低迭代调优,我们可以在空间场景中达到94%,NOW现场场景检测的准确率也达到了90%。
02
直播检测方案具备检测能力后,要想真正接入直播业务,还需要对直播流进行分帧,然后对相应的帧图片进行花屏检测。
整个后台框架
如果每天需要检测2000万张截图,即100万张截图,使用分帧截图s会有一张截图需要检测,考虑到花屏总是出现在很长一段时间内,我希望抽样时间更长,以避免浪费计算能力。