这一节主要介绍三个命令工具
- printf格式化输出
- awk管道命令使用
- diff文件对比
格式化打印: printf
模本练习文件

练习测试文件
root@ubuntu:/tmp# printf '打印格式' 实际内容
printf选项与参数:
关于格式方面的几个特殊样式:
\a 警告声音输出
\b 倒退键(backspace)
\f 清除屏幕 (form feed)
\n 输出新的一行
\r 亦即 Enter 按键
\t 水平的 [tab] 按键
\v 垂直的 [tab] 按键
\xNN NN 为两位数的数字,可以转换数字成为字符。
关于 C 程序语言内,常见的变量格式
%ns 那个 n 是数字, s 代表 string ,亦即多少个字符;
%ni 那个 n 是数字, i 代表 integer ,亦即多少整数码数;
%N.nf 那个 n 与 N 都是数字, f 代表 floating (浮点),如果有小数码数,
假设我共要十个位数,但小数点有两位,即为 %10.2f!
示例一,最模板练习文件只显示姓名和成绩,并且用tab分割

格式化输出成绩
由于 printf 并不是管线命令,因此我们得要通过类似上面的功能,将文件内容先提出来给 printf 作为后续的数据才行。 如上所示,我们将每个数据都以 [tab] 作为分隔,但是由于 Chinese 长度太长,导致 English 中间多了一个 [tab] 来将数据排列整齐!结果就看到数据对齐结果的差异了!
示例二,将上述文件,从第二行开始,分别以字符串,整数,小数点来显示:

只输出姓名成绩
%10s 代表的是一个长度为 10 个字符的字串字段,%5i 代表的是长度为 5 个字符的数字字段,至于那个 %8.2f 则代表长度为 8 个字符的具有小数点的字段,其中小数点有两个字符宽度。我们可以使用下面的说明来介绍 %8.2f 的意义:
字符宽度: 12345678 %8.2f意义:00000.00
awk:好用的数据处理工具
sed 常常作用于一整个行的处理, awk 则倾向于一行当中分成数个“字段”来处理。
root@ubuntu:/tmp# awk '条件类型1{动作1} 条件类型2{动作2} ...' filename
awk 后面接两个单引号并加上大括号 {} 来设置想要对数据进行的处理动作。 awk 可以处理后续接的文件,也可以读取来自前个指令的 standard output 。 但如前面说的, awk 主要是处理“每一行的字段内的数据”,而默认的“字段的分隔符号为 "空白键" 或 "[tab]键" ”!举例来说,我们用 last 可以将登陆者的数据取出来,结果如下所示:
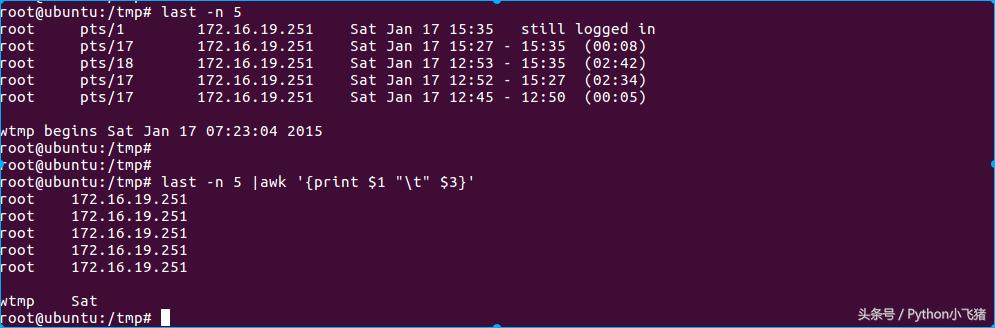
awk打印第一列和第三列
last -n 5 是取出5条登录记录
last -n 5 |awk '{print $1 "\t" $3}' 是取出帐号与登陆者的 IP ,且帐号与 IP 之间以 [tab] 隔开
$S(S>0)代表是第S列的意思,如果S=0的话,则$0代表的是一整行

输出$0一整行
awk有三个特殊的变量 NF,NR,FS
NF每一行 ($0) 拥有的字段总数
NR目前 awk 所处理的是“第几行”数据
FS目前的分隔字符,默认是空白键
示例:
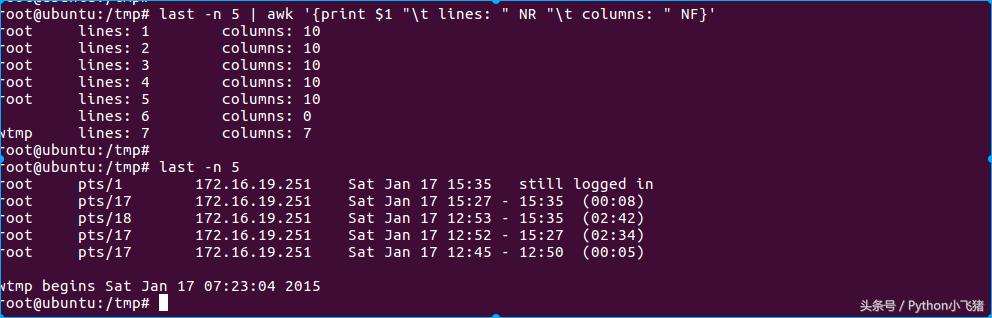
NR与NF的使用
上图可以看出NR代表行数,NF代表每行有几列
awk 的逻辑运算字符
> 大于
< 小于
>= 大于或等于
<= 小于或等于
== 等于
!= 不等于
直接看示例
在 /etc/passwd 当中是以冒号 ":" 来作为字段的分隔, 该文件中第一字段为帐号,第三字段则是 UID。那假设我要查阅,第三栏小于 10 以下的数据,并且仅列出帐号与第三栏, 那么可以这样做:
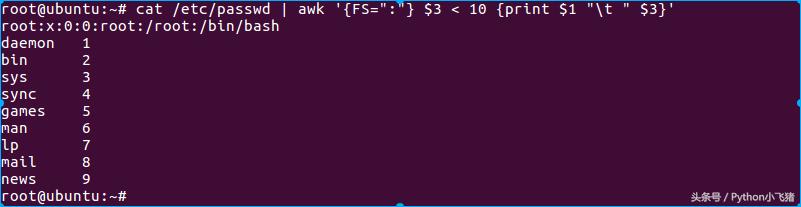
FS使用方法
有趣吧!不过,怎么第一行没有正确的显示出来呢?这是因为我们读入第一行的时候,那些变量 $1, $2... 默认还是以空白键为分隔的,所以虽然我们定义了 FS=":" 了, 但是却仅能在第二行后才开始生效。那么怎么办呢?我们可以预先设置 awk 的变量啊! 利用 BEGIN 这个关键字喔!这样做:
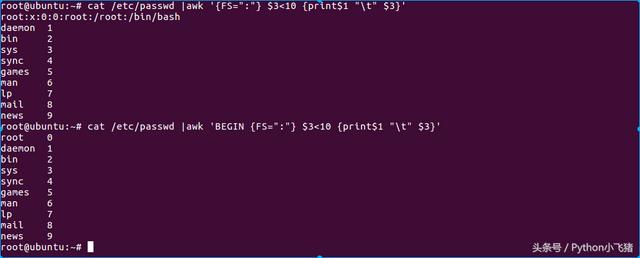
BEGIN使用方法
awk计算功能:

awk计算功能
pay.txt是模板测试文件,用此文件来计算Total
root@ubuntu:/tmp# cat pay.txt | awk 'NR==1 {printf "%10s %10s %10s %10s %10s\n",$1,$2,$3,$4,"Total"} NR>=2 {printf "%10s %10i %10i %10i %10.2f\n", $1,$2,$3,$4,$2+$3+$4}'
当NR==1时,输出第一行内容,加上"Total"列,当NR>=2时,计算2-4列的总值放置于Total下
printf是格式化输出
diff 文件对比工具
root@ubuntu:~# diff [-bBi] from-file to-file
diff选项与参数:
from-file :一个文件名,作为原始比对文件的文件名;
to-file :一个文件名,作为目的比对文件的文件名;
注意,from-file 或 to-file 可以 - 取代,那个 - 代表“Standard input”之意。
-b :忽略一行当中,仅有多个空白的差异(例如 "about me" 与 "about me" 视为相同
-B :忽略空白行的差异。
-i :忽略大小写的不同。
示例一:比对 passwd.old 与 passwd.new 的差异:
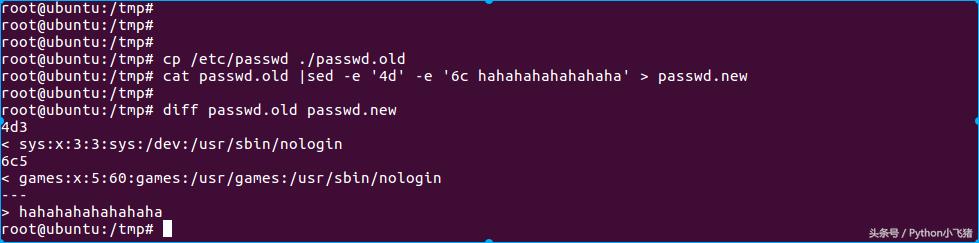
diff的用法
4d3 左边第四行被删除 (d) 掉了,基准是右边的第三行
sys:x:3:3:sys:/dev:/usr/sbin/nologin 这边列出左边文件被删除的那一行内容
6c5 左边文件的第六行被取代 (c) 成右边文件的第五行
games:x:5:60:games:/usr/games:/usr/sbin/nologin 左边文件第六行内容
hahahahahahahaha 右边文件第五行内容
还有两个文件对比的指令 cmp,patch这里不做详细解释,有兴趣的朋友们可以自己试验一把