1、前言
相信大家在知识共享的这个年代一定在网上下载了很多的文件保存以供日后有时间学习吧,毕竟硬盘空间也比较有限,下面我们就来说说我们要做的这个项目,就是搜索盘搜里的资源然后进行下载。
2、项目目标
实现搜索自己想要的文件,并且下载文件。
3、项目准备
使用sublime text 3 开发。因为此次我们需要用到交互式来完成操作,所以需要在sublime text 3 下载一个sublimeREPL插件来进行辅助开发。
4、项目实现
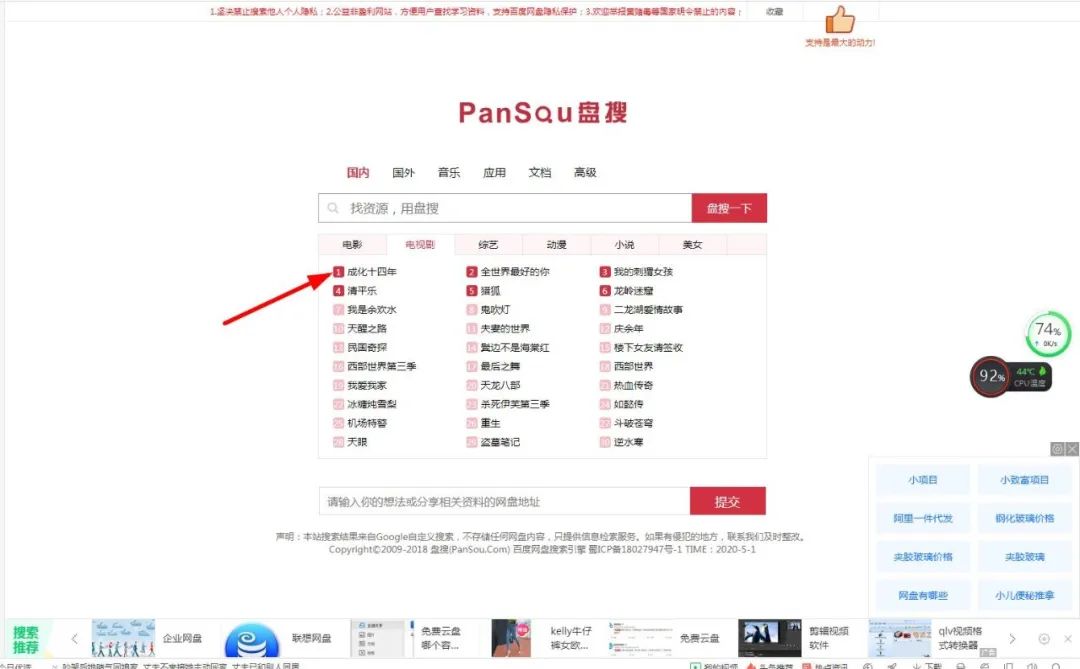
(1)打开盘搜,并随意打开一个链接,如下图所示:
(2)然后可以看到这个画面,如下图所示。
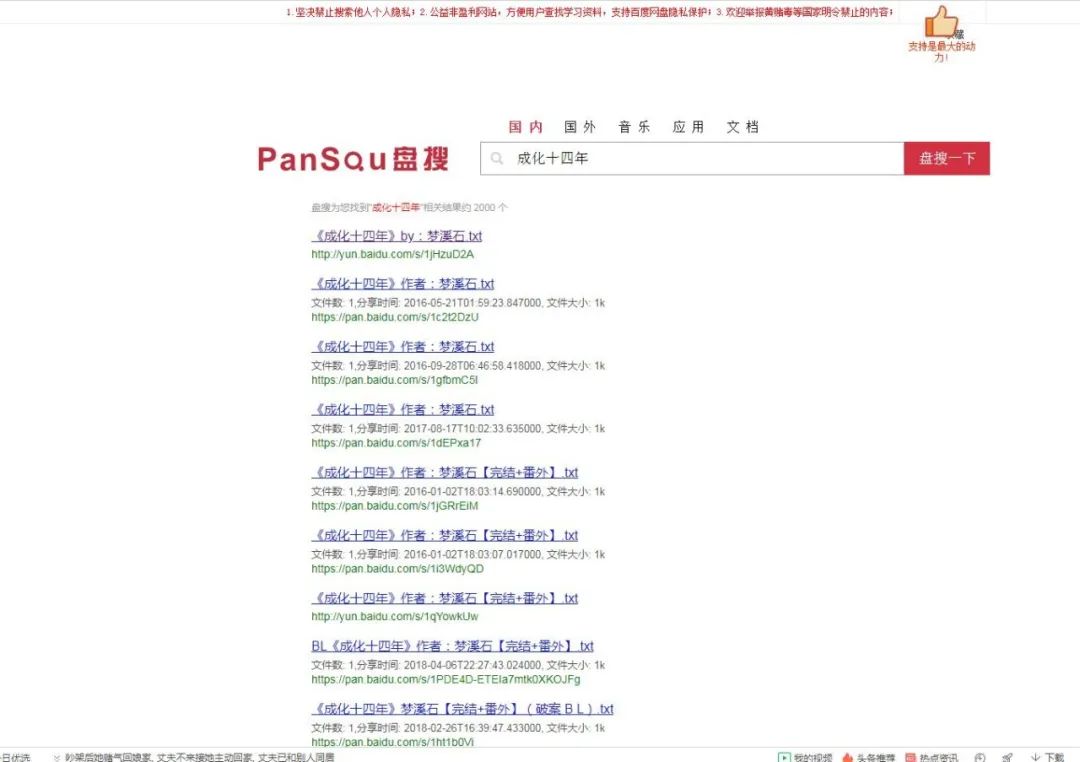
(3)此时这个网页地址为:
http://www.pansou.com/?q=成化十四年
由此可以看出它是一个get请求。于是requests.get搞起来,这样我们就实现了第一步,搜索。于是,可以这样写代码:
import requests
def down(content):
content=input('请输入要下载的文件名')
rep=requests.get('http://www.pansou.com/?q=' str(content))
rep.encoding='utf-8'
(4)这样就得到了上个页面中的网页源代码,我们通过搜索相关关键字发现竟然搜不到:
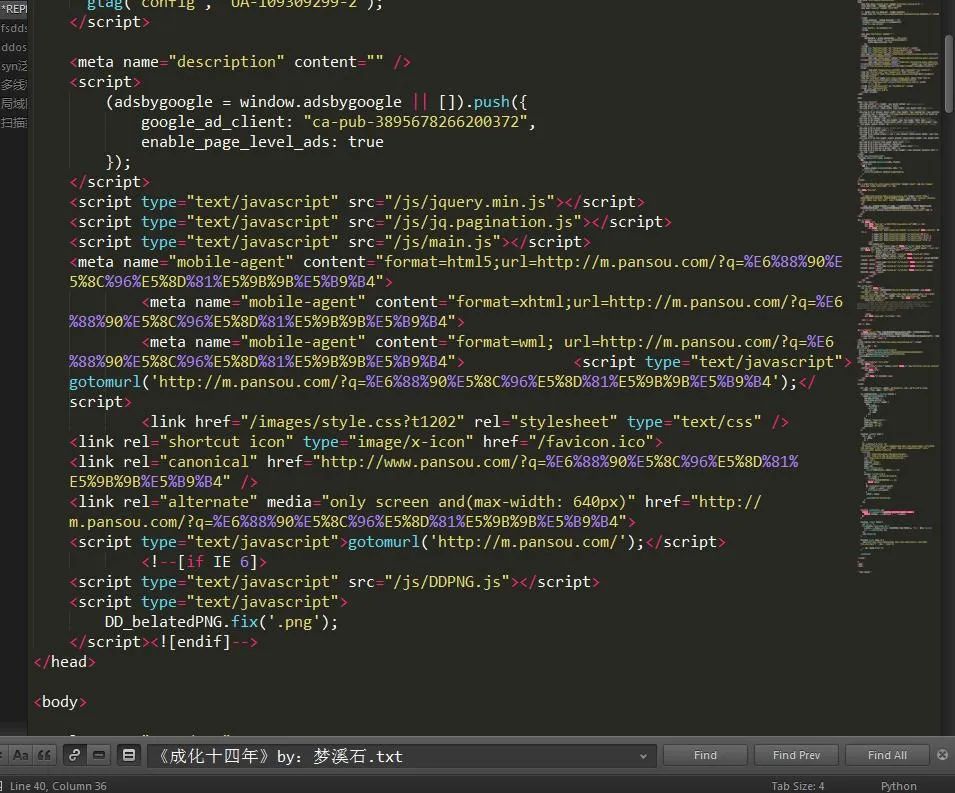
(5)那么这是怎么回事?原来这是因为ajax异步加载导致的部分关键代码显示不出来。这可就犯难了,换句话说这就触及到我的知识点盲区了。
因为小编并未学过前端,只知道有ajax这回事,哪里知道这个问题怎么产生怎么解决了。不过不用怕,还好小编有一个大绝招,那就是找接口。我找呀找,终于被我找到了,哎,功夫不负苦心人。如图所示:
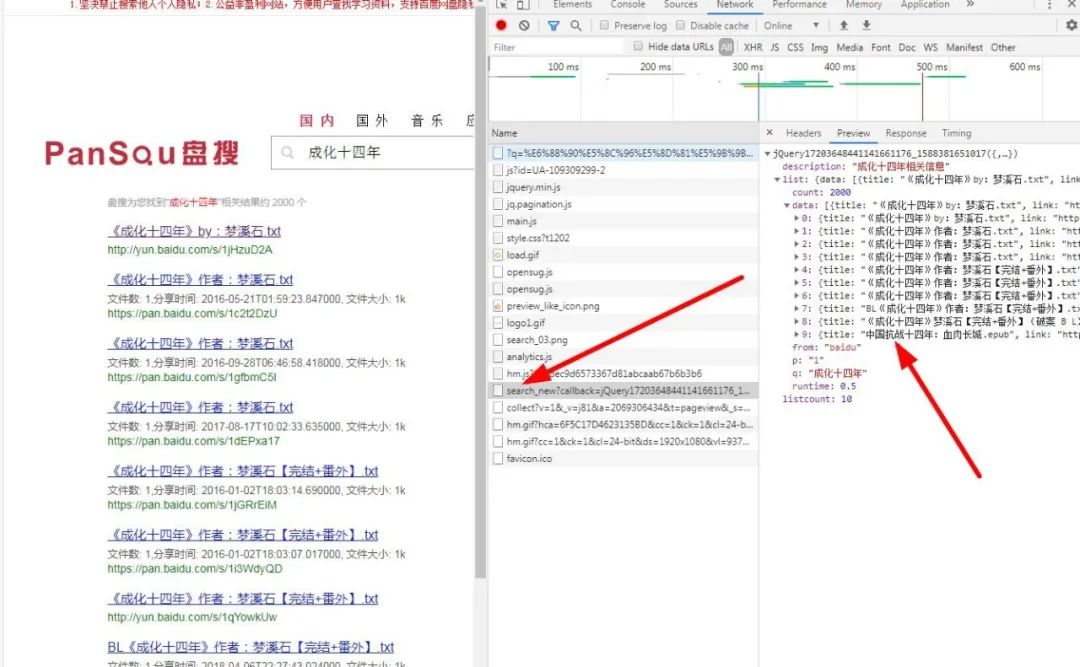
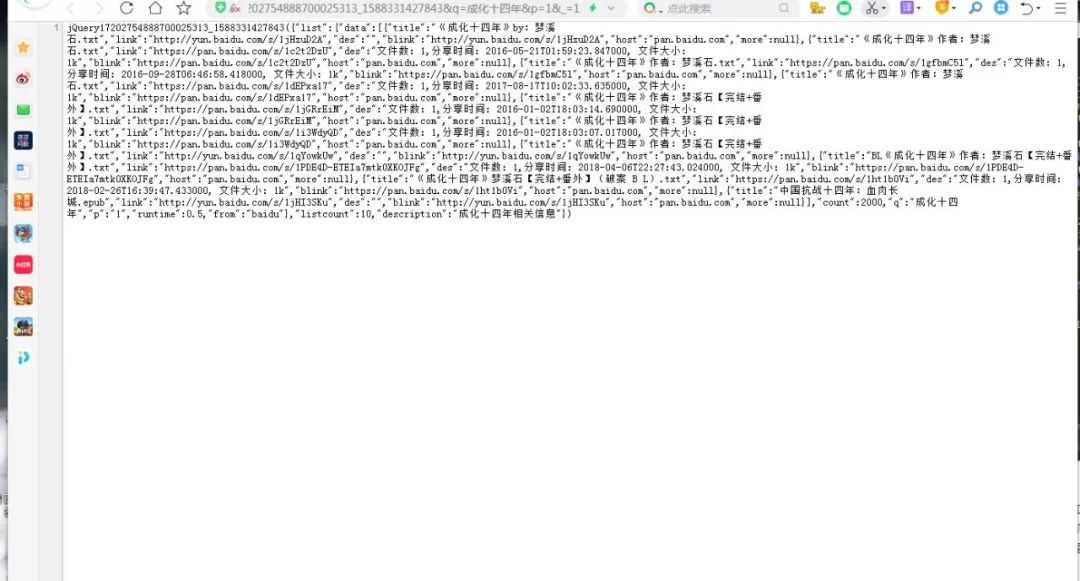
(6)发现这是个json格式的所以我们现在可以将他进行读取,如图:
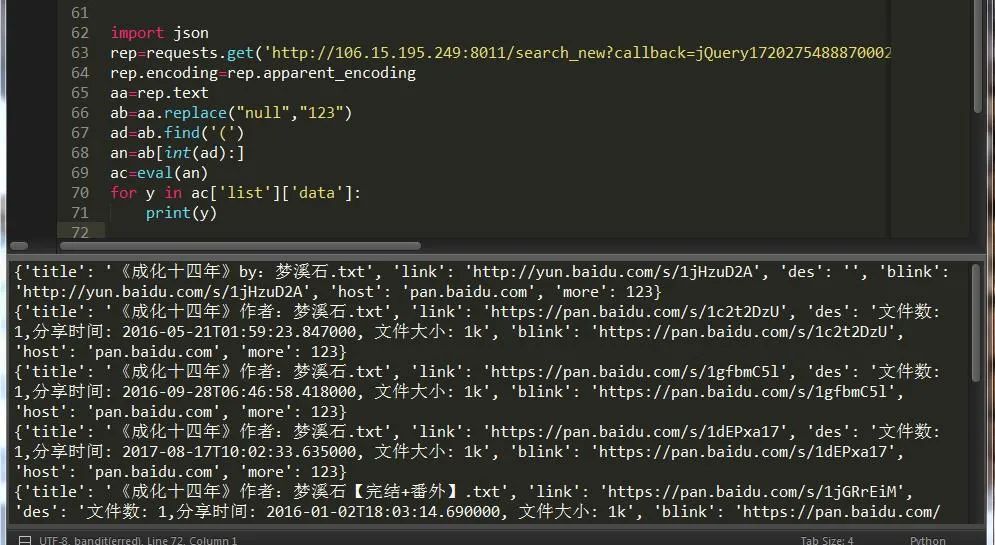
(7)不容易啊,json的坑很多,于是决定用字典。哈哈哈哈,果然适合自己的才是最香的。
找到了这些东西我们就可以把他们提取出来啦,这样我们就提取出了第一页的所有结果,要想提取第二页的结果只需将p的结果改为2即可。
最终的结果,如图:
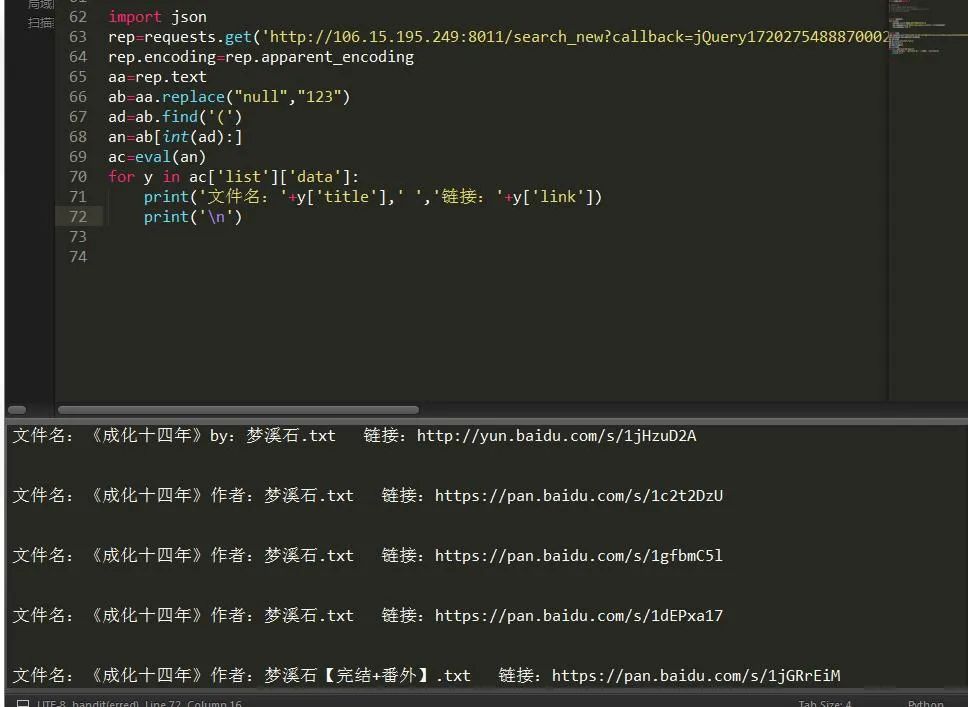
(8)接下来我们强化下程序,让他具有交互功能,供用户选择。
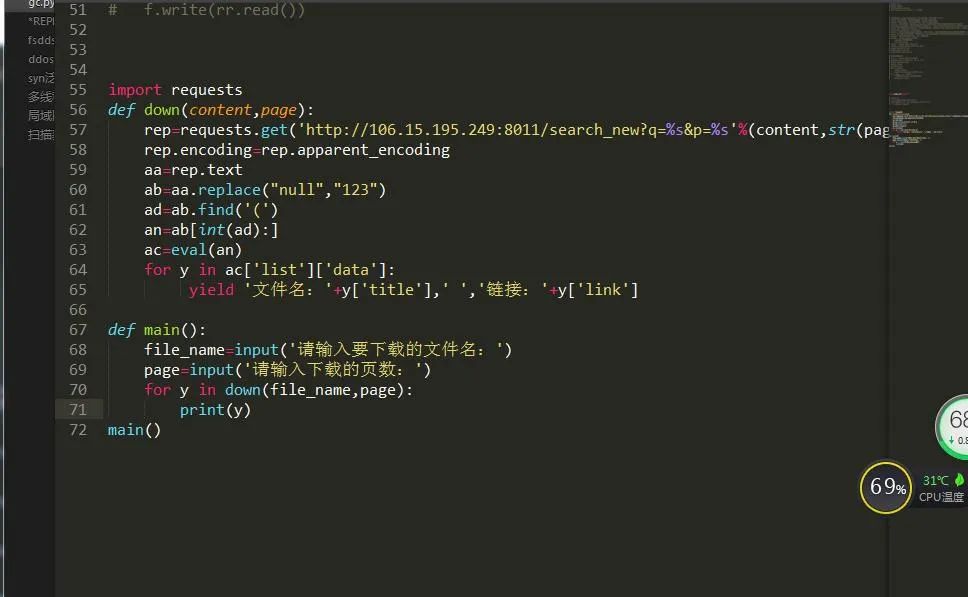
(9)但是我们了解到callback一般都是可变的函数,所以真正能用上的就只有两个参数,q和p,于是:
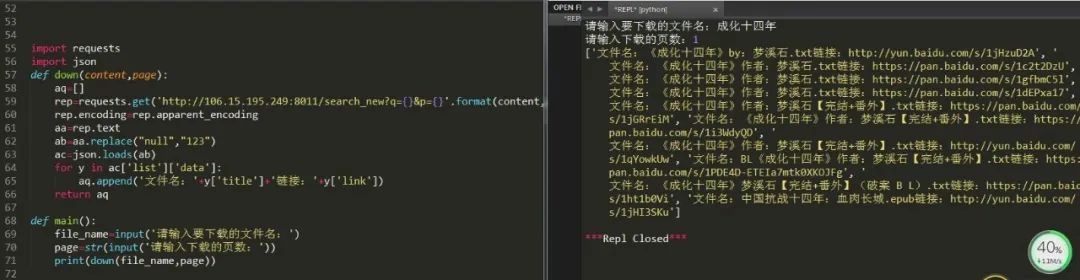
这样就完成了指定页面的文件浏览。
下载的话也比较简单,直接将链接复制到浏览器中即可,这样就完成了一个最简单的搜索引擎了。
5、小结
(1)不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
(2)本文基于Python网络爬虫,利用爬虫库,打造了一款简易的Python搜索引擎。
(3)实现的时候,总会有各种各样的问题,切勿眼高手低,勤动手,才可以理解的更加深刻。