二叉树很重要
树是数据结构中的重中之重,尤其以各类二叉树为学习的难点。单就面试而言,在 leetcode 中二叉树相关的题目占据了300多道。同时,二叉树在整个算法板块中还起到承上启下的作用:不但是数组和链表的延伸,又可以作为图的基础。
举个例子,比如说我们的经典算法「快速排序」和「归并排序」,对于这两个算法,你有什么理解?如果你告诉我,快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后序遍历,那么我就知道你是个算法高手了。
一些概念
结点
结点是数据结构中的基础,是构成复杂数据结构的基本组成单位
树
树(Tree)是n(n>=0)个结点的有限集。n=0时称为空树。在任意一颗非空树中:
- 有且仅有一个特定的称为根(Root)的结点;
- 当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1、T2、......、Tn,其中每一个集合本身又是一棵树,并且称为根的子树。
此外,树的定义还需要强调以下两点:
- n>0时根结点是唯一的,不可能存在多个根结点,数据结构中的树只能有一个根结点。
- m>0时,子树的个数没有限制,但它们一定是互不相交的。
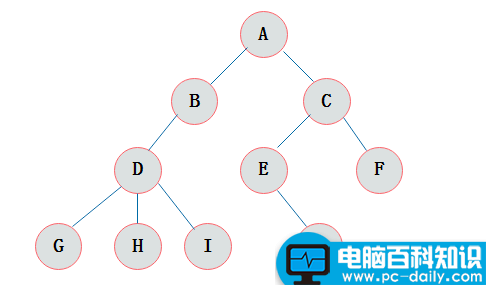
一颗普通的树
结点的度
结点拥有的子树数目称为结点的度。
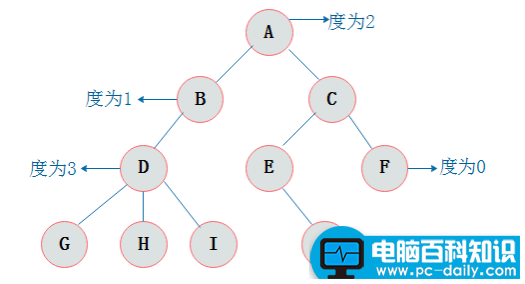
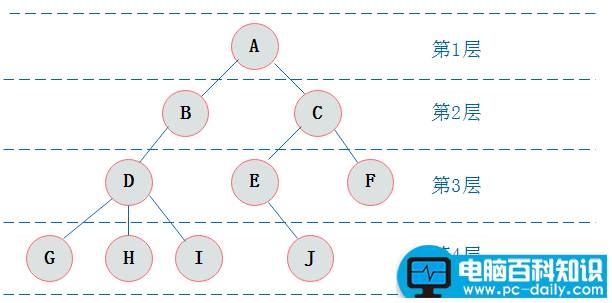
结点层次
从根开始定义起,根为第一层,根的孩子为第二层,以此类推
二叉树
定义
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
二叉树特点
- 1)每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
- 2)左子树和右子树是有顺序的,次序不能任意颠倒。
- 3)即使树中某结点只有一棵子树,也要区分它是左子树还是右子树。
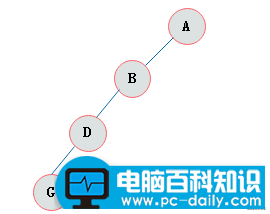
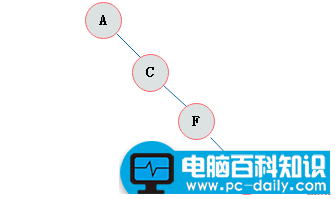
斜树
所有的结点都只有左子树的二叉树叫左斜树。所有结点都是只有右子树的二叉树叫右斜树。这两者统称为斜树。
二叉搜索树
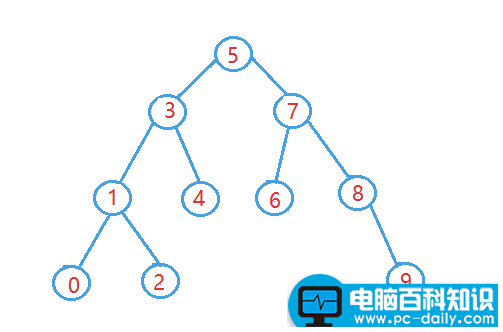
二叉搜索树又被称为二叉排序树,那么它本身也是一棵二叉树,那么满足以下性质的二叉树就是二叉搜索树:
- 1、若左子树不为空,则左子树上左右节点的值都小于根节点的值
- 2、若它的右子树不为空,则它的右子树上所有的节点的值都大于根节点的值
- 3、它的左右子树也要分别是二叉搜索树
平衡二叉树
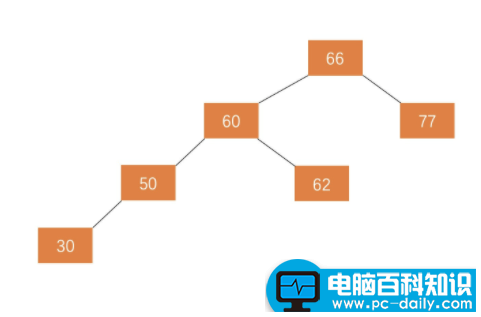
平衡二叉树(Balanced BinaryTree)又被称为AVL树。它具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
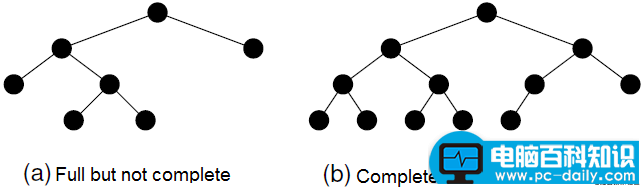
满二叉树
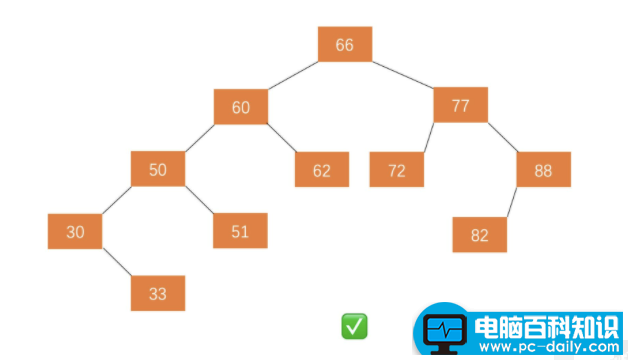
在一棵二叉树中。如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。 满二叉树的特点有:
- 1)叶子只能出现在最下一层。出现在其它层就不可能达成平衡。
- 2)非叶子结点的度一定是2。
- 3)在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多。
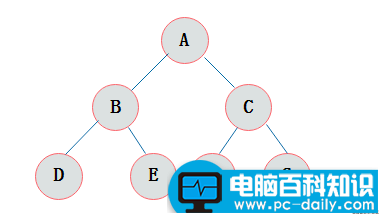
完全二叉树
从根往下数,除了最下层外都是全满(都有两个子节点),而最下层所有叶结点都向左边靠拢填满。 构造一颗完全二叉树就是【从上到下,从左往右】的放置节点。
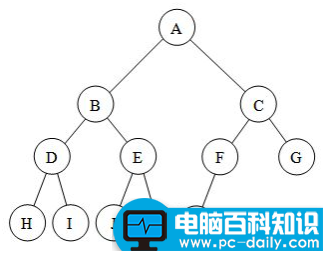
满二叉树和完全二叉树的区别
- 左侧为满二叉树但不是完全二叉树,要补全的话可以给第二层最左节点下加两个子节点,或删除当前最下层的两个节点。
- 右侧是一颗完全二叉树但并不是满二叉树,因为最下层最后一个节点没有兄弟节点,即其父节点只有一个子节点,不满,补满的话再加一个右子节点即可【满二叉树的节点要么没孩子,要有就一定得是俩】。
二叉树的存储结构(序列化)
顺序存储
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,并且结点的存储位置,就是数组的下标索引。
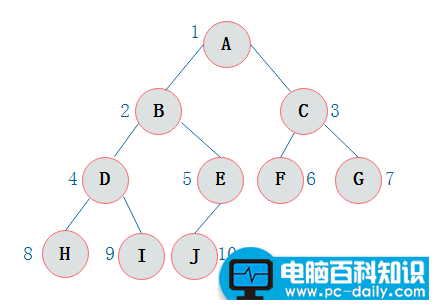
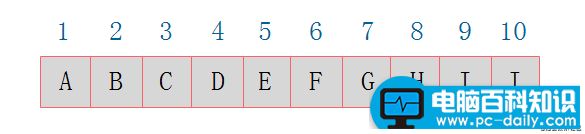
当二叉树为完全二叉树时,结点数刚好填满数组。那么当二叉树不为完全二叉树时,采用顺序存储形式如何呢?下图浅颜色的为空
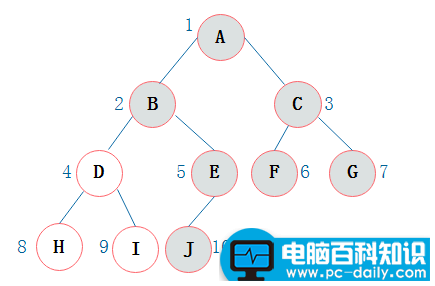
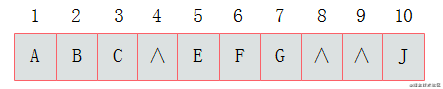
其中,∧表示数组中此位置没有存储结点。此时可以发现,顺序存储结构中已经出现了空间浪费的情况。 因此,顺序存储一般适用于完全二叉树。
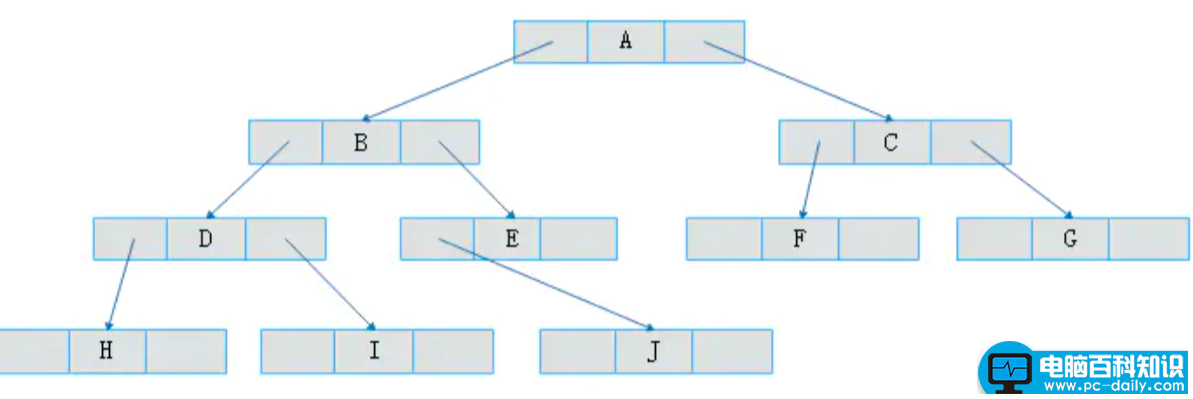
二叉链表
既然顺序存储不能满足二叉树的存储需求,那么考虑采用链式存储。由二叉树定义可知,二叉树的每个结点最多有两个孩子。因此,可以将结点数据结构定义为一个数据和两个指针域。表示方式如图所示:

二叉树遍历
二叉树的遍历是指从二叉树的根结点出发,按照某种次序依次访问二叉树中的所有结点,使得每个结点被访问一次,且仅被访问一次。 二叉树的访问次序可以分为四种:
- 前序遍历
- 中序遍历
- 后序遍历
- 层序遍历
前序遍历:根-左-右
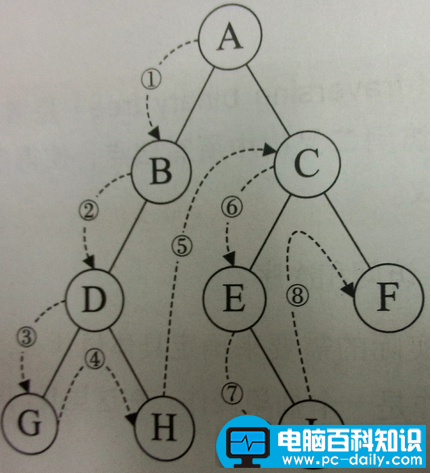
中序遍历:左-根-右
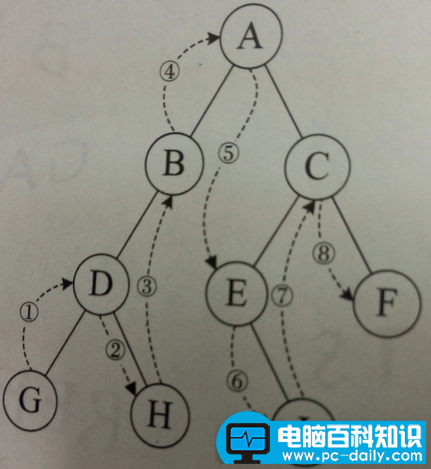
后序遍历:左-右-根
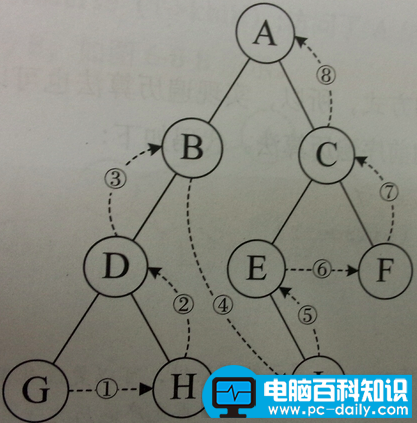
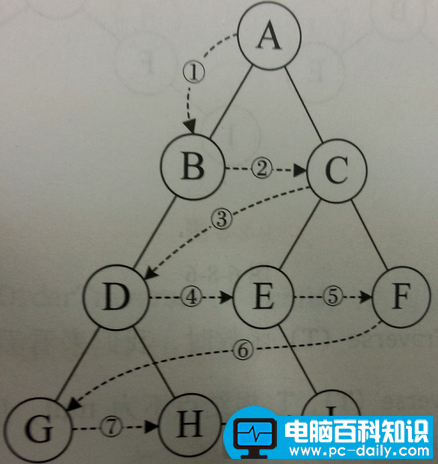
层序遍历:从根节点出发,依次访问左右孩子结点,再从左右孩子出发,依次它们的孩子结点,直到节点访问完毕
代码
递归遍历模板
public static class Node{ public int value; public Node left; public Node right; public Node(int v){ value =v;
}
} //遍历模板 public static void f(Node head){ if (head == null){ return;
} //1 f(head.left); //2 f(head.right); //3 }
复制代码
递归前序遍历
//前序遍历 根--》左--》右 public static void pre(Node head){ if (head == null){ return;
}
System.out.println(head.value);
pre(head.left);
pre(head.right);
}
复制代码
递归中序遍历
//前序遍历 根--》左--》右 public static void pre(Node head){ if (head == null){ return;
}
System.out.println(head.value);
pre(head.left);
pre(head.right);
}
复制代码
递归后序遍历
//后序遍历 左--》右--》根 public static void pos(Node head){ if (head == null){ return;
}
pos(head.left);
pos(head.right);
System.out.println(head.value);
}
复制代码
非递归前序遍历
//前序遍历 根--》左--》右 public static void unRecursivePre(Node head){ if (head!=null){
Stack<Node> stack = new Stack<>();
stack.add(head); while (!stack.isEmpty()){
head = stack.pop();
System.out.println(head.value); if (head.left!=null){
stack.add(head.left);
} if (head.right!=null){
stack.add(head.right);
}
}
}
}
复制代码
非递归中序遍历
//前序遍历 左--》根--》右 public static void unRecursiveIn(Node head){ if (head!=null){
Stack<Node> stack = new Stack<>();
stack.add(head); while (!stack.isEmpty() || head!=null){ if (head!=null){
stack.push(head);
head = head.left;
}else {
head = stack.pop();
System.out.println(head.value);
head = head.right;
}
}
}
}
复制代码
非递归后序遍历
//左--》右--》根 public static void unRecursivePos(Node head){ if (head!=null){
Stack<Node> s1 = new Stack<>();
Stack<Node> s2 = new Stack<>();
s1.push(head); while (!s1.isEmpty()){
head =s1.pop();
s2.push(head); if (head.left!=null){
s1.push(head.left);
} if (head.right!=null){
s1.push(head.right);
}
} while (!s2.isEmpty()){
System.out.println(s2.pop());
}
}
}
复制代码
层遍历
public static void level(Node head){ if (head == null){ return;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head); while (!queue.isEmpty()){
Node cur = queue.poll();
System.out.println(cur.value); if (cur.left!=null){
queue.add(cur.left);
} if (cur.right!=null){
queue.add(cur.right);
}
}
}
复制代码
序列化(模板方法)
public static class Node{ public int value; public Node left; public Node right; public Node(int v){ value =v;
}
} public static Queue<String> fSerial(Node head){
Queue<String> ans = new LinkedList<>();
fpres(head,ans); return ans;
} public static void fpres(Node head,Queue<String> ans){ if (head == null){
ans.add(null);
}else { //1 ans.add(String.valueOf(head.value)); //2 fpres(head.left,ans); //3 fpres(head.right,ans);
}
}
复制代码
计算二叉树的最大宽度
public static class Node { public int value; public Node left; public Node right; public Node(int v) { value = v;
}
} public static int maxWidthUseMap(Node head) { if (head == null) { return 0;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head); // key 在哪一层 value HashMap<Node, Integer> levelMap = new HashMap<>();
levelMap.put(head, 1); int curLevel = 1;//当前正在统计的层 int curLevelNodes = 0; //当前层的宽度是多少。 int max = 0; while (!queue.isEmpty()) {
Node cur = queue.poll(); int curNodeLevel = levelMap.get(cur); if (cur.left != null) {
levelMap.put(cur.left, curNodeLevel + 1);
queue.add(cur.left);
} if (cur.right != null) {
levelMap.put(cur.right, curNodeLevel + 1);
queue.add(cur.right);
} if (curLevelNodes == curLevel) {
curLevelNodes++;
} else {
max = Math.max(max, curLevelNodes);
curLevel++;
curLevelNodes = 1;
}
}
max = Math.max(max, curLevelNodes); return max;
} public static int maxWidthNoMap(Node head) { if (head == null) { return 0;
}
Queue<Node> queue = new LinkedList<>();
queue.add(head);
Node curEnd = head;//当前层,最右节点是谁 Node nextEend = null;//下一层,最右侧节点是谁 int max = 0; int curLevelNodes = 0;//当前节点数 while (!queue.isEmpty()) {
Node cur = queue.poll(); if (cur.right != null) {
queue.add(cur.right);
nextEend = cur.left;
} if (cur.left != null) {
queue.add(cur.left);
nextEend = cur.left;
}
curLevelNodes++; if (cur == curEnd){
max = Math.max(max,curLevelNodes);
curLevelNodes =0; //当前节点清0 curEnd = nextEend;
}
} return max;
}
复制代码
二叉树模板代码解决折纸问题
问题
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。 此时折痕是凹下去的,即折痕凸起的方向指向纸条的背面。
如果从纸条的下边向上方对折2次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕,下折痕和上折痕。
给定一个输入参数N,代表纸条都从下边向上方连续对折N次。请从上到下打印所有的折痕的方向。
例如:N=1时,打印: down 。N=2时,打印:down down up
规律,大于一次后,每次折痕出现的位置都是在上次折痕的上方出现凹折痕,下方出现凸折痕。所以我们没必要构建这颗树,就可以用递归思维解决(即 :参考二叉树递归遍历模板)
对应的树结构按层输出为: 1凹 2凹 2凸 3凹 3凸 3凹 3凸 复制代码
public static void printAllFolds(int N) { // 先从头结点出发,i初始值为1,切第一次的头结点折痕为凹折痕 printProcess(1, N, true);
} // 递归过程,来到了某一个节点, // i是节点的层数,N一共的层数,down == true 凹 down == false 凸 public static void printProcess(int i, int N, boolean down) { if (i > N) { return;
}
printProcess(i + 1, N, true);
System.out.println(down ? "凹 " : "凸 ");
printProcess(i + 1, N, false);
} public static void main(String[] args) { int N = 3;
printAllFolds(N);
}
复制代码
二叉树的递归套路
套路总结
- 1)假设以X节点为头,假设可以向X左树和X右树要任何信息
- 2)在上一步的假设下,讨论以X为头节点的树,得到答案的可能性(最重要)
- 3)列出所有可能性后,确定到底需要向左树和右树要什么样的信息
- 4)把左树信息和右树信息求全集,就是任何一棵子树都需要返回的信息S
- 5)递归函数都返回S,每一棵子树都这么要求
- 6)写代码,在代码中考虑如何把左树的信息和右树信息整合出整棵树的信息
判断二叉树是否是搜索二叉树(利用套路)
public static class Node { public int value; public Node left; public Node right; public Node(int data) {
this.value = data;
}
} //节点的可以得到的信息 public static class Info {
boolean isBST; public int min; public int max; public Info(boolean is, int mi, int ma) {
isBST = is; min = mi; max = ma;
}
} //开始组装节点返回信息 (重要) public static Info process(Node head) { if (head == null) { return null;
} Info leftInfo = process(head.left); Info rightInfo = process(head.right);
int min = head.value;
int max = head.value; if (leftInfo != null) { min = Math.min(min, leftInfo.min); max = Math.max(max, leftInfo.max);
} if (rightInfo != null) { min = Math.min(min, rightInfo.min); max = Math.max(max, rightInfo.max);
} //设置可能性 boolean isBST = false; if (
(leftInfo == null ? true : (leftInfo.isBST && leftInfo.max < head.value))
&&
(rightInfo == null ? true : (rightInfo.isBST && rightInfo.min > head.value))
) {
isBST = true;
} return new Info(isBST, min, max);
} public static boolean isBST(Node head) { if (head == null) { return true;
} return process(head).isBST;
}
复制代码
判断一个树是不是平衡二叉树(利用套路解)
public static boolean isBalanced(Node head) { return process(head).isBalaced;
} // 左、右要求一样,Info 信息返回的结构体 public static class Info { public boolean isBalaced; public int height; public Info(boolean b, int h) {
isBalaced = b;
height = h;
}
} public static Info process(Node X) { if (X == null) { return new Info(true, 0);
}
Info leftInfo = process(X.left);
Info rightInfo = process(X.right); int height = Math.max(leftInfo.height, rightInfo.height) + 1; boolean isBalanced = true; // 设置不是的情况 if (!leftInfo.isBalaced || !rightInfo.isBalaced || Math.abs(leftInfo.height - rightInfo.height) > 1) {
isBalanced = false;
} return new Info(isBalanced, height);
}
复制代码
二叉树和快速排序和归并排序的联系
前文讲到,,快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后序遍历。为什么快速排序和归并排序能和二叉树扯上关系?我们来简单分析一下他们的算法思想和代码框架:
快排
快速排序的逻辑是,若要对 nums[lo..hi] 进行排序,我们先找一个分界点 p,通过交换元素使得 nums[lo..p-1] 都小于等于 nums[p],且 nums[p+1..hi] 都大于 nums[p],然后递归地去 nums[lo..p-1] 和 nums[p+1..hi] 中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
void sort(int[] nums, int lo, int hi) { /****** 前序遍历位置 ******/ // 通过交换元素构建分界点 p int p = partition(nums, lo, hi); /************************/ sort(nums, lo, p - 1);
sort(nums, p + 1, hi);
}
复制代码
先构造分界点,然后去左右子数组构造分界点,你看这不就是一个二叉树的前序遍历吗?
归并排序
归并排序的逻辑,若要对 nums[lo..hi] 进行排序,我们先对 nums[lo..mid] 排序,再对 nums[mid+1..hi] 排序,最后把这两个有序的子数组合并,整个数组就排好序了。
归并排序的代码框架如下:
void sort(int[] nums, int lo, int hi) { int mid = (lo + hi) / 2;
sort(nums, lo, mid);
sort(nums, mid + 1, hi); /****** 后序遍历位置 ******/ // 合并两个排好序的子数组 merge(nums, lo, mid, hi); /************************/ }
复制代码
先对左右子数组排序,然后合并(类似合并有序链表的逻辑),你看这是不是二叉树的后序遍历框架?
贪心算法
贪心算法,又名贪婪法,是寻找最优解问题的常用方法,这种方法模式一般将求解过程分成若干个步骤,但每个步骤都应用贪心原则,选取当前状态下最好/最优的选择(局部最有利的选择),并以此希望最后堆叠出的结果也是最好/最优的解。 主要理解如下:
- 1)最自然智慧的算法
- 2)用一种局部最功利的标准,总是做出在当前看来是最好的选择
- 3)难点在于证明局部最功利的标准可以得到全局最优解
- 4)对于贪心算法的学习主要以增加阅历和经验为主
贪心算法和堆
堆是一种非常灵活的数据结构,我们可以单独地使用它来解决很多有趣的问题。而且,由于堆的定义本来就有最优的含义,所以它与贪心算法有着天然的联系。
而堆这种数据结构本质是一个完全二叉树。
贪心法的基本步骤:
- 步骤1:从某个初始解出发;
- 步骤2:采用迭代的过程,当可以向目标前进一步时,就根据局部最优策略,得到一部分解,缩小问题规模;
- 步骤3:将所有解综合起来。
应用场景(切金条)
一块金条切成两半,是需要花费和长度数值一样的铜板的。 比如长度为20的金条,不管怎么切,都要花费20个铜板。 一群人想整分整块金条,怎么分最省铜板?
例如,给定数组{10,20,30},代表一共三个人,整块金条长度为60,金条要分成10,20,30三个部分。
如果先把长度60的金条分成10和50,花费60; 再把长度50的金条分成20和30,花费50;一共花费110铜板。 但如果先把长度60的金条分成30和30,花费60;再把长度30金条分成10和20, 花费30;一共花费90铜板。 输入一个数组,返回分割的最小代价。
public static int lessMoney(int[] arr) {
PriorityQueue<Integer> pQ = new PriorityQueue<>(); for (int i = 0; i < arr.length; i++) {
pQ.add(arr[i]);
} int sum = 0; int cur = 0; while (pQ.size() > 1) {
cur = pQ.poll() + pQ.poll();
sum += cur;
pQ.add(cur);
} return sum;
}
复制代码
ps:文中部分图片来自网络,侵删!