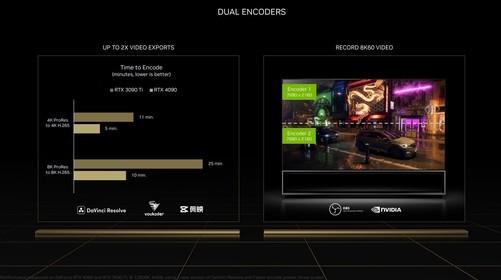
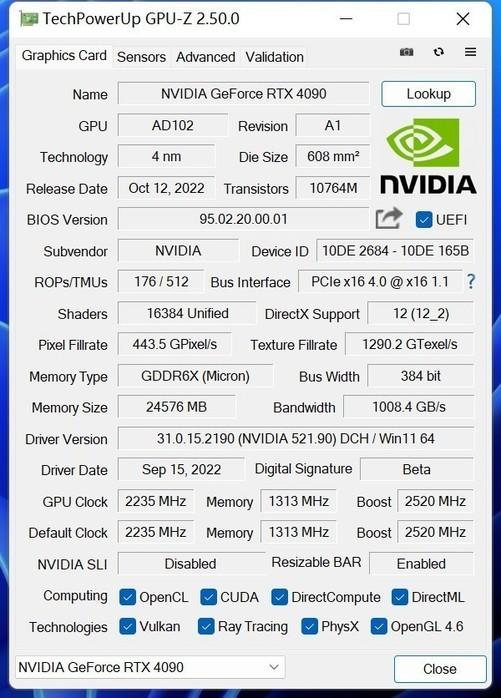
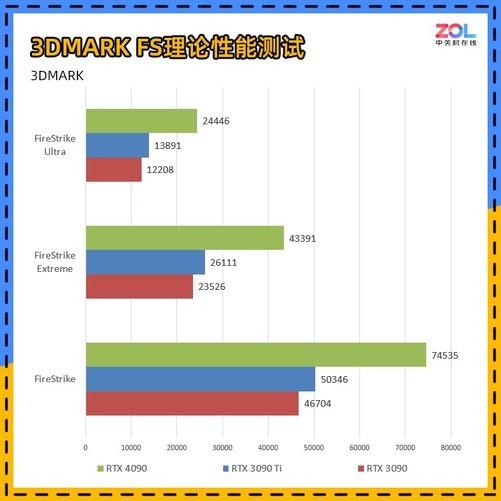
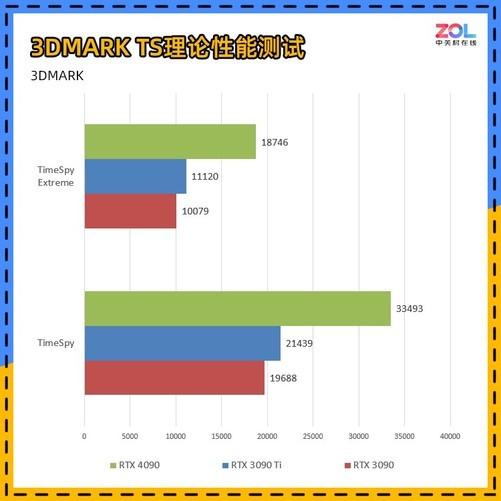
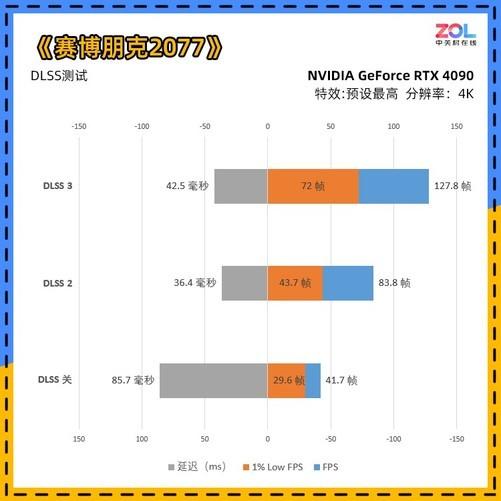
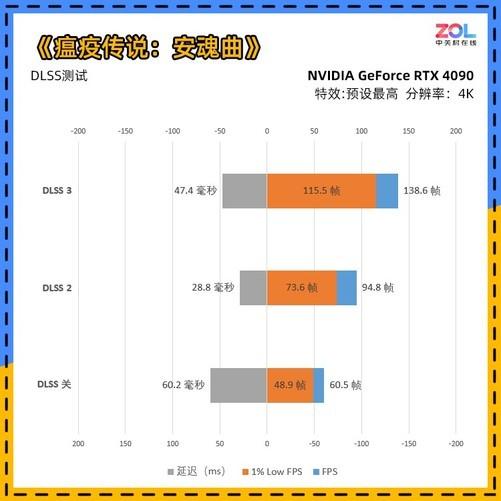
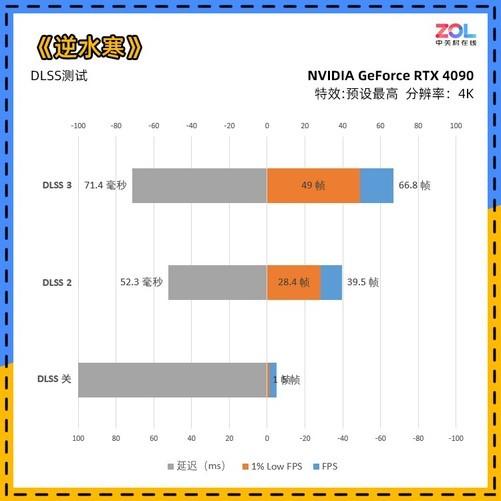
NVIDIA RTX 40系列显卡终于见到了我们。按照以往的做法,游戏级的80显卡通常是第一个见到我们的,但这次首先推出的是90级产品。

事实上,根据目前的情况,GeForce RTX 为了照顾仍在市场上销售的4090率先推出RTX 30系产品。还记得在RTX 30系列显卡推出时,大部分RTX 其实20系显卡已经停产,整体更新节奏明显。
而目前GeForce RTX 3090的价格基本不到1万元,已经停产。所以在这个时候推出GeForce RTX 4090不足以影响RTX 整体销售30系。

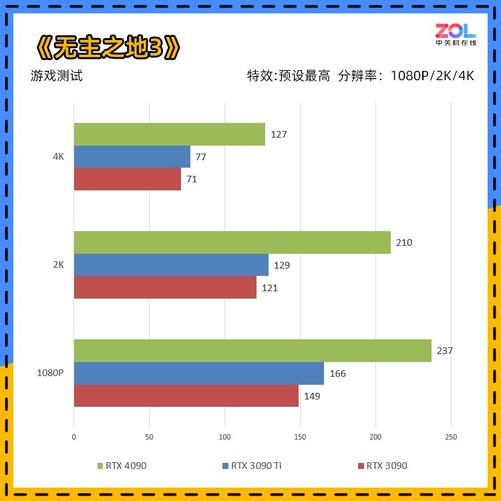
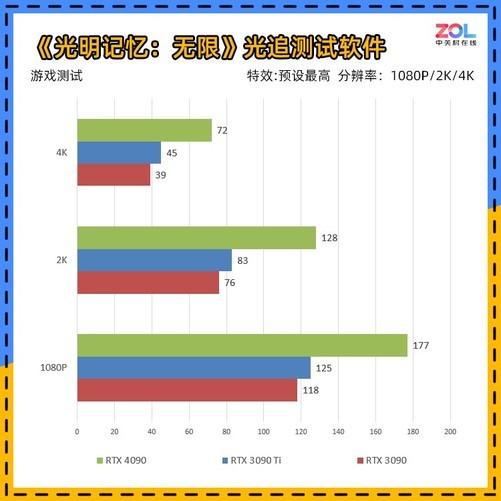
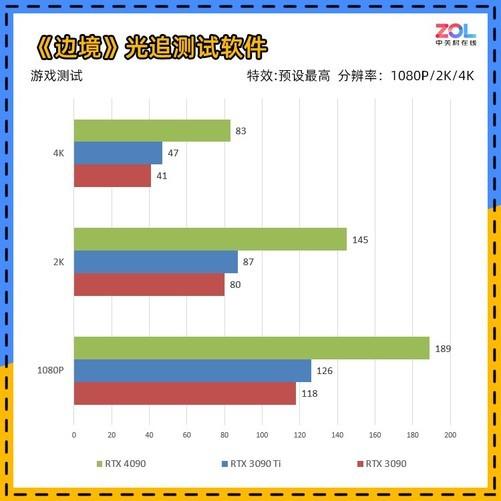
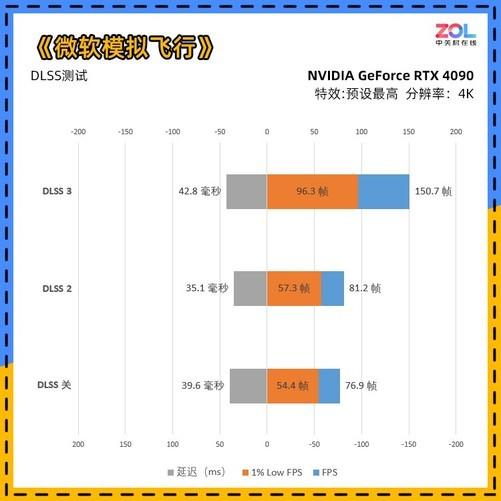
每次90级产品NVIDIA官实官方很少宣传游戏领域,但即使这次性能差距这么大,即使是NVIDIA侃侃也谈到了它的游戏性能。
顺便说一次NVIDIA将限量推出GeForce RTX 4090 FE北京时间10月12日晚9点,公版将在京东上市。喜欢公版设计或者想收藏的玩家一定要开始,只有拿在手里,才能感受到什么是满分工业设计。
01 NVIDIA GeForce RTX 4090 概览今年的GeForce RTX 4090在外观上变化不大,但包装一如既往的精致,这次NVIDIA还加入了环保理念。

外包装仍然使用哑光黑色纸箱,可以清楚地看到GeForce RTX 字体90字体的变化,GeForce RTX英文字样更流畅,数字更厚。
从侧面可以看出,除了外圈的硬纸盒外,显卡的包装都是黑色瓦楞纸。盒子两侧有黑色胶带,防止运输损坏。

打开的包装有点像帐篷的形状。这个性能怪物静静地躺在那里,有趣的是,显卡周围的装饰线条有自己的震惊效果。

拿出显卡后,包装里还附上了16张pin转8pin*4的转接线。其实本次GeForce RTX 建议电源和4090GeForce RTX 3090 Ti相同,都是850W,所以如果在RTX 配备高瓦数电源的30系玩家可以放心升级。

NVIDIA GeForce RTX 4090 FE显卡的整体尺寸为304×137×61mm,占用3槽空间。其实长度比较RTX 30系列显卡没有变化,甚至比RTX 3090 Ti还少了10mm,但是整体质感和重量都有所提高,整张卡大概是2.2kg,这仍然是一个以简单设计而闻名的公共版本。很难想象每个家庭AIC显卡会有多重。

NVIDIA GeForce RTX 4090的整体设计依然沿用RTX 30系列显卡的外观,但由于架构升级,热量增加,散热自然需要同步升级。本次的GeForce RTX 4090风扇尺寸再次增加,基本达到显卡整体框架直径。在散热风扇增加的基础上,最大气流动态增加20%,同噪声等级气流动态增加15%。

视频输出接口仍然使用HDMI 2.1 DP 1.4a*四接口设计。HDMI 2.1可支持4K 120Hz HDR、8K 60Hz HDR,现阶段的产品完全够用。
至于高呼声DP 2.0.事实上,目前大多数消费游戏显示器都没有实装,DP 1.4a标准也可以支持8K 60Hz显示刷新率。所以,总的来说,绝对够用。
而且,我们真的需要这么极端的规格吗?大家都知道羊毛出在羊身上的道理。
此外,由于公共版采用的双轴流散热系统,视频输出界面可以看到大量的散热片,与上一代相同。

本次GeForce RTX 4090整卡功耗450W,采用单16pin辅助供电。目前,一些电源制造商已经发布了最新的ATX 3.0标准高端电源,自带12VHPWR的16pin最高可支持600个供电接口W供电。因此,如果没有意外,也许下一代显卡也会使用这样的单16pin来供电。
虽然目前所有显卡厂商基本都会附上转接线,但是8pin*4的混乱程度可想而知。如果条件允许,一个ATX 3.0标准电源不要太干净。
需要注意的是,目前适用于RTX 30系列的12pin接口和电源转接器RTX 40系列显卡不兼容。
另外在RTX 即使在40系列显卡中,也是首发旗舰GeForce RTX 4090也不支持NVLink,所以不可能重现过去的四路泰坦。
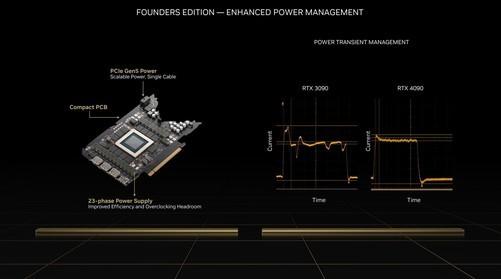
最后来看看GeForce RTX 4090内部的PCB板材,仍采用深V”的异形PCB,它仍然紧凑地布置所有的组件,没有浪费,并在如此紧凑的环境中配备了20个 3相供电。整齐,堪称艺术品。
NVIDIA还强调,在高负荷下,GeForce RTX 4090的供电更稳定,不会有剧烈的电压和电流波动。
02 Ada Lovelace 姓甚名谁?让我们来看看这次推出NVIDIA Ada Lovelace架构,我们先从Ada Lovelace和这个人相比Ampere,这个似乎更奇怪。
Ada Lovelace英国数学家、计算机程序创始人(1815-1852)建立了循环和子程序的概念,被称为世界上第一个程序员。
Ada她的父亲从小就有很高的数学天赋,称她为平行四边形公主Charles Babbage称她为数字女巫。在19岁时Ada嫁给了她以前的科学家庭教师,婚后她对数学的热情并没有减弱。

1842年至1843年翻译9个月Babbage《分析机概论》的备忘录写了很多注释,其中给出了计算机Bernoulli详细说明数求解。由此,Ada它被广泛认为是世界上第一个程序员。
以她的名字命名的语言——ada语言已成为美军开发战斗机等尖端武器的语言。
从几行简短的生活简介中不难看出Ada虽然生命只经历了37个短暂的春秋,但足以被后人铭记。
这就是为什么这次NVIDIA RTX 在40的先行宣传中,使用了以未来敬传奇slogan,下面我们详细分析一下,这次Ada Lovelace还有哪些创新和超越?
03 NVIDIA Ada Lovelace架构本次发布的GeForce RTX 40系统显卡是全新的NVIDIA Ada Lovelace建筑结构,采用TSMC 4nm定制工艺(TSMC 4 nm NVIDIA Custom Process),旗舰核心AD102达到了恐怖760亿而在RTX 30系显卡中有280亿个。
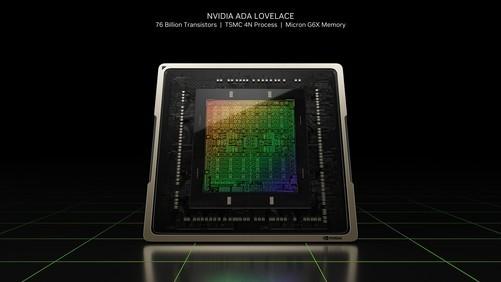
与上一代NVIDIA Ampere相比,NVIDIA Ada Lovelace具有相同的功率2倍以上性能提升。最高可达到90-TFLOPS本次发布的着色器数据吞吐量GeForce RTX 4090则达到83-TFLOPs,相比上一代NVIDIA Ampere则只有40-TFOPs。


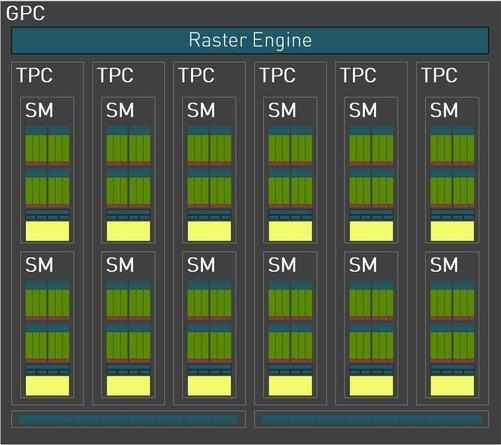
完整的AD102核心共有18432个CUDA,包括12个图形处理集群(GPCs), 72个纹理处理集群(TPCs), 144流式多处理器(SMs)。
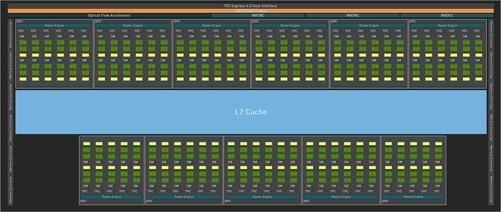 完整的AD102核心共有18432个CUDA,包括12个图形处理集群(GPCs), 72个纹理处理集群(TPCs), 144流式多处理器(SMs)。第三代光追核心144(RT Cores)、第四代张量核心576(Tensor Cores)。另外可以看到Boost频率也从1.9GHz猛增到了2.5GHz。另一点没有体现在架构图上,AD102核心还包括288FP64双精度浮点核心SM 2),用于保证FP正确处理64代码,包括FP核心代码64张。一般来说,单精度浮点运算用于深度学习模型训练,而双精度浮点运算用于数值模拟。通常游戏卡会被砍掉FP这样既节省了成本,而且对游戏本身也没有影响。保留专业卡FP64的目的是更高精度的训练和计算。这个数据只提到了AD102核心288FP64.不知道后续推出的产品有没有变化。
完整的AD102核心共有18432个CUDA,包括12个图形处理集群(GPCs), 72个纹理处理集群(TPCs), 144流式多处理器(SMs)。第三代光追核心144(RT Cores)、第四代张量核心576(Tensor Cores)。另外可以看到Boost频率也从1.9GHz猛增到了2.5GHz。另一点没有体现在架构图上,AD102核心还包括288FP64双精度浮点核心SM 2),用于保证FP正确处理64代码,包括FP核心代码64张。一般来说,单精度浮点运算用于深度学习模型训练,而双精度浮点运算用于数值模拟。通常游戏卡会被砍掉FP这样既节省了成本,而且对游戏本身也没有影响。保留专业卡FP64的目的是更高精度的训练和计算。这个数据只提到了AD102核心288FP64.不知道后续推出的产品有没有变化。 了解完整GA再来看看102核心。RTX 其实知道4090的核心。RTX 对于4090的参数,我们也可能知道后续可能推出的Ti系列到底有什么区别?
了解完整GA再来看看102核心。RTX 其实知道4090的核心。RTX 对于4090的参数,我们也可能知道后续可能推出的Ti系列到底有什么区别?
相比完整的GA102来说,RTX 4090共有16384个CUDA,其中包含11个GPC、64个TPC以及128个SM单元,第三代RT Cores第四代128Tensor Cores为512个。

事实上,根据完整的架构图,这次可以看到Ada架构整体结构变化不大,从SM单元可以清楚地确认相同的单元FP32 CUDA核心,同样的FP32/INT32混合CUDA核心,同样的L一级缓存等。当然,每个SM单元内部的Tensor Core升级为第四代。
但变化最显著的是第三代光追核心,我们结合两代架构。在第二代光追核心中,负责边界交叉测试Box Intersection Engine发动机和负责三角形交叉试验的发动机Triangle Intersection Engine引擎。
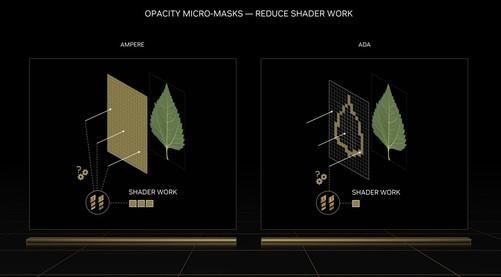
 在第三代光追核心中,增加了两个新引擎:
在第三代光追核心中,增加了两个新引擎:Opacity Micro-Map Engines(OMM)
和Displaced Micro-Mesh Engines(DMM),
这两个新的硬件单元可以大大提高光追性能(详细介绍具体原理)。至此,每2个SM一个单元组成TPC单元,每6组TPC一个单元组成完整的GPC顶层单元(5组将出现在一些核心中TPC组成一个GPC单位的情况)。
而每个GPC单元还配备了独立的光栅引擎和两组ROP分区(每组8个ROP单元)。
不再介绍太多关于数字的部分。毕竟这个架构图的大面和NVIDIA Ampere除了性能,架构基本相同。Ada还有哪些架构升级?
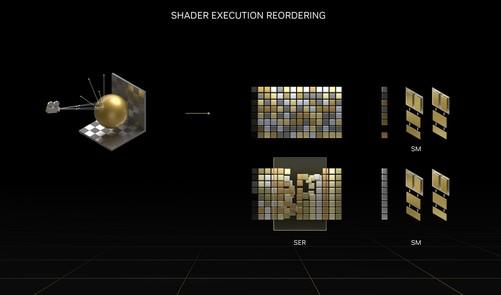
Shader Execution Reordering (SER)着色器重新排序
SER其主要功能是提高着色器的性能,它能将低效的工作负荷动态重组为更高效的工作负荷。光线跟踪的性能有了很大的提高。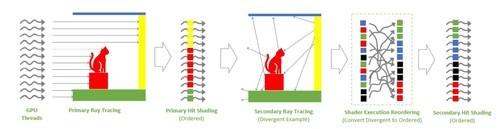
简单地说,GPU执行类似工作效率最高。然而,随着光追逐效果的增强,每个场景可能会有数百万光照射在不同的材料上,我们知道不同材料的反射率和反射效果也不同。因此,为着色器创造了大量、发散、低效的工作负荷。
SER将这些凌乱的指令重新分类,动态重组为更有效的工作负荷。根据NVIDIA的说法,SER着色器的性能可以提高2倍,游戏帧率可以提高25%。 举个简单的例子,当光线第一次从发射端到碰撞端是非常有规律的射线时,与物体碰撞后的二次光追会有大量不规则的发散反射,对光追负载非常高。从图中可以看出,SER为了发挥着色器的最大性能,可以对这些指令进行二次排序。
举个简单的例子,当光线第一次从发射端到碰撞端是非常有规律的射线时,与物体碰撞后的二次光追会有大量不规则的发散反射,对光追负载非常高。从图中可以看出,SER为了发挥着色器的最大性能,可以对这些指令进行二次排序。幸运的是,这样一个实用的功能不是RTX 40系专利,易于集成SDK,游戏开发商目前需要集成在游戏中。此外,由于它是一个通用的逻辑,后续也可以直接集成Windows的API在中间,游戏开发者不需要特别引用,直接调用系统API即可。
 可以说SER对于手持RTX 20系及以上(
能够
可以说SER对于手持RTX 20系及以上(
能够