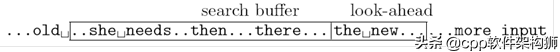general0100量产工具
()
最近实现了一个ZIP压缩数据的解压程序认为有必要ZIP详细总结压缩格式。数据压缩是一门涉及通信原理和计算机科学的学科。在通信原理中,它通常被称为信源编码。在计算机科学中,它通常被称为数据压缩,两者本质上没有区别,在数学家眼里都是映射。一方面,在通信过程中,有必要压缩待传输的数据,以减少带宽需求;另一方面,当计算机存储数据时,为了减少磁盘容量需求,也会压缩文件,虽然网络带宽越来越高,压缩不像90年代初那么紧迫,但在许多情况下仍然需要,原因之一是压缩数据容量减少,磁盘访问IO时间也缩短,虽然压缩和解压过程会消耗CPU资源,但是CPU计算资源增长迅速,但磁盘IO但资源变化缓慢,如当前主流SATA如果磁盘仍然是7200转,硬盘仍然是7200转IO压力转化到CPU一般来说,系统运行速度可以提高。压缩作为一种非常典型的技术,会应用到很多很多场合下,比如文件系统、数据库、消息传输、网页传输等等各类场合。压缩作为一种非常典型的技术,将应用于文件系统、数据库、信息传输、网页传输等多种场合。虽然压缩涉及到许多术语和技术,但不用担心,博客试图描述它。此外,本文所涉及的压缩算法非常主流和精致。ZIP压缩过程应该更容易理解其他相关的压缩算法。
1、引子压缩可分为无损压缩和有损压缩。有损是指压缩后原始信息无法完全恢复,但压缩率可以很高,主要用于视频、语音等数据的压缩。由于少量信息丢失,人们很难检测到,或者没有必要这么清楚地阅读和听;无损压缩用于文件等必须完全恢复信息的场合,ZIP自然是一种无损压缩压缩。在通信原理中介绍数据压缩时,往往从信息理论的角度引出香农定义的熵概念。这方面的介绍太多了。在这里,从最原始的想法出发,如何设计算法以达到压缩的目的。而ZIP为我们提供了相当好的案例。而ZIP为我们提供了相当好的案例。
虽然我们不讨论信息论中复杂的概念,但我们应该从两位信息论大牛开始。因为他们奠定了今天大部分无损数据压缩的核心,包括ZIP、RAR、GZIP、GIF、PNG等等大多数无损压缩格式。这两头牛的名字分别是Jacob Ziv和Abraham Lempel,1977年,两位以色列人发表了一篇论文《A Universal Algorithm for Sequential Data Compression》,从名称上看,这是一种所谓的通用压缩算法,这意味着这种压缩算法对数据类型没有限制。不过我觉得不用仔细看论文,因为博主是通信专业的。PHD,它看起来也很焦虑,但我们可以看到它的想法仍然很简单,主要是因为它看起来很复杂IEEE有些杂志就是这个特点,需要从数学上证明这种压缩算法有多优秀,比如一个各种状态的随机序列(不需要调查什么是各种状态的随机序列)。在这种压缩算法之后,你是否能接近信息论的极限(即熵的概念)等等,但在理解它的想法之前,我认为除非你想发表论文,否则没有必要深入研究这些东西。这两位大牛提出的算法被称为LZ一年后,两头大牛又提出了一种类似的算法,叫做LZ78.思想相似,ZIP这个算法是基于的LZ77的思想演变过来的,但ZIP对LZ77编码后的结果继续压缩,直到难以压缩。除了LZ77、LZ78.还有很多变种算法,基本都是以LZ开头,如LZW、LZO、LZMA、LZSS、LZR、LZB、LZH、LZC、LZT、LZMW、LZJ、LZFG等等,很多,LZW也比较流行,GIF记得用动画格式。LZW。我也写过解码程序,以后有时间可以再写一篇,但是感觉和LZ77这些类似,写作不必要。我也写过解码程序,以后有时间可以再写一篇,但是感觉和LZ77这些类似,写作不必要。
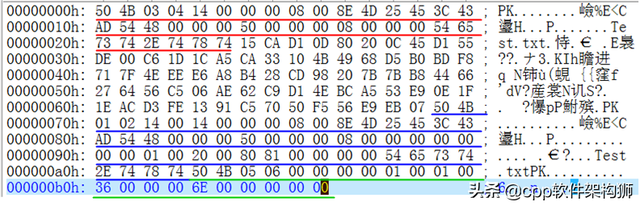
ZIP作者是一个名字Phil Katz这个人是开源界的悲剧传奇人物。虽然二三十年前,开源这个词并没有现在这么风起云涌,但无论他在哪个时代,总有一些有黑客精神的牛人心中充满了自由。Phil Katz这个人是个牛逼程序员,成名于DOS我个人没有经历过那个时代。Windows98开始接触电脑的人只是从书中得知,当时网速很慢,拨号只用了几十个Kb(比特不是字节)猫,56Kb其实是这种猫的最高速度,在ADSL该技术出现后迅速被淘汰。当时硬盘也是记录文件的,但是软盘是在电脑之间复制文件的。我大一的时候用过这个东西。记得最高容量是1.44MB,这还是200X年的软盘,以前的软盘容量具体多大就不知道了,Phil Katz上网还不到1990年,WWW事实上,它没有出现。当然,没有浏览器。当时为什么要上网?基本上类似于网网络管理部门敲击各种命令,所以你实际上可以聊天,去论坛,不是吗件,你必须慢慢死去,所以压缩在那个时代非常重要。当时,一家商业公司提供了一个名称ARC在那个时代,压缩软件可以让你聊得更快,当然要付费,Phil Katz感觉不舒服,就写了一个PKARC,免费,看名字知道是兼容的ARC所以网友都用PKARC了,ARC公司自然不开心,把哥们告上法庭,说涉及知识产权等等,结果Phil Katz坐牢了。。。。牛人是牛人, 在监狱里冥想,决定超越整个人ARC牛逼算法出来了,牢里适合思考,用了两周就整理出来了,叫PKZIP,不仅免费,这次还开源,直接发布源代码,因为算法不同,不涉及知识产权,所以ZIP流行,但是Phil Katz这个人没有从里面赚到一分钱,还是很穷,由于饮酒过多等诸多原因,2000年死在一家汽车酒店。英雄逝去,精神永存。现在我们用它UE打开ZIP文件,我们可以看到开头的两个字节是PK两个字符的ASCII码。英雄逝去,精神永存。现在我们用它UE打开ZIP文件,我们可以看到开头的两个字节是PK两个字符的ASCII码。
2.一个案例的入门思考好了,Phil Katz牢里到底想到了什么?压缩数据的算法是什么?我们想一个简单的例子:
生,容易。活,容易。生活,不容易。
如果上述句子没有压缩,如果使用Unicode编码,每个字用两个字节表示。为什么是两个字节?Unicode这是一个国际标准。制定了英文字符、日文字符、韩文字符、中文字符、拉丁字符等常见字符的标准。显然,最多可以用两个字节表示2^16=65536字符,那么65536就够了吗?其实生僻字很多,比如光康熙字典里有几万个汉字,其实是不够的,那么扩展到四个字节吗?也可以,空间变大了,可以包含更多的字符,但一方面,扩展到四个字节必须保证足够吗?另一方面,四个字节是不是太浪费空间,只是为了那些一般情况下不会出现的生僻字?因此,在正常情况下,使用两个字节表示,当出现的单词时,使用四个字节表示。事实上,这反映了信息理论中数据压缩的基本思想。频繁出现的字符表示较短;稀有的可以表示较长(一般不会),从而减少整体长度。除了Unicode,ASCII编码是针对英文字符的编码方案,可以用一个字节。除了这两种编码方案,还有很多区域编码方案,比如GB2312可以编码中文简体字,Big5可编码中文繁体字。如果两个文件都使用编码方案,那就没问题了,但考虑到国际化,尽量使用Unicode这个国际标准。不过这个跟ZIP没关系,纯属背景介绍。
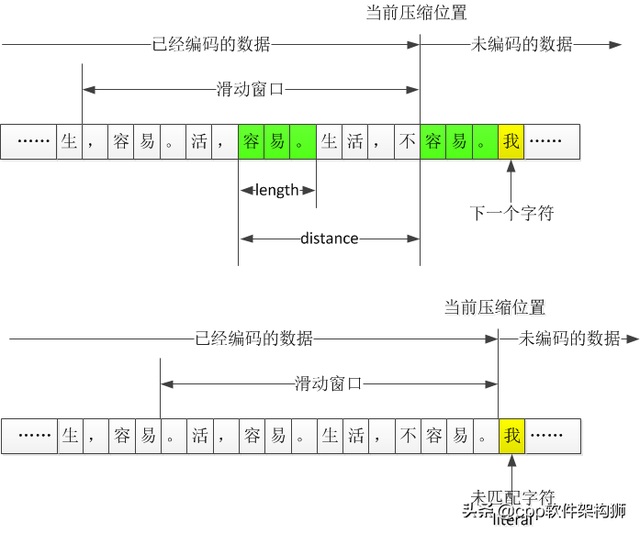
好了,回到我们前面提到的例子,如果用普通的话,总共有17个字符(包括标点符号)。Unicode总共是17*2=34字节。能压缩吗?大家一眼就能看出里面有很多重复的字符,比如里面有很多容易的词(其实很容易加句号三个字),第一次出现的时候用普通的字符。Unicode,容易第二次出现。它可以用(距离和长度)来表示。距离意味着下一个字符与前面重复的字符分开,长度意味着有几个重复的字符。上面的第二个例子很容易。意思是(5,3),距离为5个字符,长度为3。解压缩时,解决这个地方时,向前跳5个字符,复制这个位置的连续3个字符,完成解压缩。这其实不是指针的概念吗?没错,和指针很像,但是在数据压缩领域,一般叫字典编码。为什么叫字典?我们去查一个字的时候,总是先去目录找字在哪一页,然后翻到那一页。指针不一样。指针不是内存的地址。为了操作一个内存,我们先得到指针,然后去那个内存。所谓的指针、字典、索引、目录等术语,不同的背景可能有不同的名称,但我们必须理解它们的本质。若使用(5、3)这种表示方法,原本需要用6个字节表示,现在只需记录5、3即可。那5和3怎么记录呢?一种方法自然还是可以用Unicode,所以这相当于节省了两个字节,但有两个问题,第一个问题是如何知道这两个字符是正常的5和3,还是这只是一个特殊的标志?所以前面要加前面添加一个标志来区分下一个标志Unicode代码是指普通字符,还是指距离和长度Unicode,则直接查Unicode代码表,如果是距离和长度,则向前移动一段距离并复制。第二个问题是压缩程度不好不好,所以,感觉压缩不多,如果重复字符更长,更划算,因为距离 长度就够了,但比如这个例子,如果在5和3之前加一个特殊的字节,不就是3个字节,最好不要压缩。咋办呢?能否再次压缩(5,3)这个整数?以下是我们前面提到的一个基本原则:少出现整数多编比特,多出现整数少编比特。那么,3、4、5、6、7、8、9这些距离谁出现得多呢?谁出现的少?谁知道?
压缩之前当然不知道,不过扫描一遍不就知道了?比如后面重复的字符串容易。按照前面的规则,可以说是(7、3),即与前面重复的字符串距离为7,长度为3。(7,3)指着前面和自己一样的字符串。那为什么不指第一个容易呢?指着第二个容易。”呢?若指第一个,则不是(7、3),即(12、3)。当然,表示(12、3)也可以减压,但有一个问题,就是12这个值比7大,大了怎么了?我们在生活中会发现一些常见的规律,重复现象往往是局部的。例如,当你和一个人说话时,你经常很快重复一句话,但你不会每五个小时重复一次。这个特征也存在于文件中。到处都是这样的例子。例如,当你编程时,你定义了一个变量int nCount,这个nCount一般来说,你很快就会使用它,不会离得很远。我们前面提到的距离代表你说这句话需要多长时间。这个距离一般不大。在这种情况下,应以最接近当前字符串的字符串为记录依据(即最接近自己的重复字符串)。在这种情况下,所有标记都是短距离的,如3、4、5、6、7,而不是3、5、78、965等,如果大部分是短距离,所以这些短距离可以用较短的比特来表示,较长的距离不是很常见,而是用较长的比特来表示。这样, 整体表示长度会减少。这样, 整体表示长度会降低。好了,我们之前已经得到了(5、3)、(7、3)的重复记录,距离有两种:5、7;长度只有1:3。咋编码?越短越好。
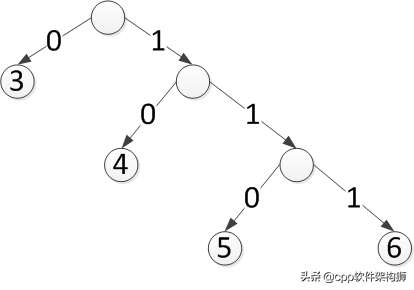
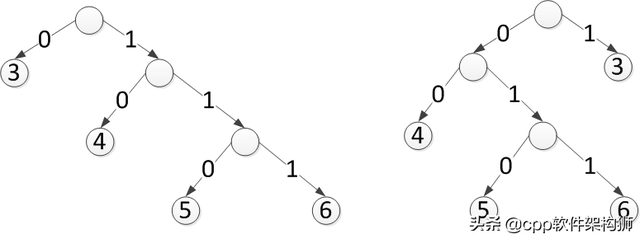
既然比特越短越好,3是0,5是10,7是11,好吗?这样(5,3),(7,3)只需要表示为100,110,不是很短吗?好像可以,好像很高效。
但解压缩遇到10这两个比特的时候,怎么知道10表示5呢?这种表示方法是一种叫做代码表的映射表。上述例子的代码表如下:
3-->0
5-->10
7-->11
这个代码表也必须传输或记录在压缩文件中,否则压缩无法解决,但在记录代码表后,整体空间会变大,不会发挥压缩的作用吗?如何记录代码表?代码表记录也是一堆数据,也需要编码吗?码表能继续压缩吗?不需要新的码表吗?压缩是一个永无止境的过程吗?作为一名入门级学生,我可能会想到这一点 儿就