首先我们看看正常的读取数据过程:
with open('test.txt','r',encoding='utf-8') as f:
#很多时候由于数据量比较大,所以并不建议一次性读取,这里我们选择的是逐行一次读取数据
for i in f:
pass
在读取数据的过程中有时候会因为某一行数据中有一些特殊字符而出现编码错误,
这里我们先看一张报错的图片:
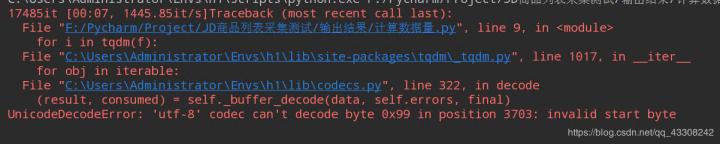
从报错中我们可以看到这里说是:utf-8编解码器不能解码字节0x9g在位置3703的无效字节,出现这个错误的时候我第一时间想到的是通过异常处理直接跳过,但是想想try加在哪里呢?加在 for i in f: 这里吗?但是想想这样就算跳过了异常那不还是拿不到后面的数据吗?加 for循环里面就更加不可能了,因为出错是错现在读取过程中,而不是读取之后。
突然发现这个问题真的很恼火呀,如果是数据量比较小我倒是可以直接打开文件到出错的地方将错误数据修改,或者将那条数据删除都行,但是文件太大了,此时又无法通过打开文件去修改。之后在朋友的提醒下我发现可以通过在读取的时候将数据以其他的方式来编码,这个时候是可以正常读取到数据的。
with open('test.txt','r', encoding='ISO-8859-1') as f:
for i in f:
pass
这里我们将编码格式改为 ISO-8859-1 ,此时我们将数据打印出来看看,

这都是什么东西啊,我的数据明明是中文的,现在成这样了,这也不是我想要的结果啊。不要着急,接下来的操作就是将你的数据还原了。
with open('test.txt','r', encoding='ISO-8859-1') as f:
for i in tqdm(f):
#此处将数据打印出来的时候我们会发现数据中中文部分会如上图一样。
print(i)
#因此处可能还是会因为数据中的特出字符导致报错,所以添加一个try在这里
#假如该条数据出错你可以选择不要或者选择将该条数据记录都行,这个看个人了。
try:
#在这里我们将读取出来的数据先用 ‘ISO-8859-1’格式给它编码,然后通过‘utf-8’给它解码
x = i.encode('ISO-8859-1').decode('utf-8')
except:
x = ''
if x != '':
#此处打印出来的你就会发现你需要的数据出来了。
print(x)
with open('test1.txt', 'a', encoding='utf-8') as f:
f.write(x)
将打印结果贴在此处:
